
A Brief Visual Introduction to Gradients and Gradient Descent
We explore gradients and gradient descent - vital concepts used in machine learning.

In calculus, the gradient is a measure of steepness. For a simple function – measuring the gradient is fairly easy; calculate the change in height divided by the base length. As an example, the gradient of the function f(x) = 8x – 3 is 8 – or to put it simply, it also equates to its derivative!!
For scalar fields, the gradient of a scalar field f represents the direction of fastest ascent. As an example, if we take the scalar field / function plotted below:

The gradient plotted over its surface is:

As you can probably tell, the resultant vector field points in the direction of fastest ascent (i.e. the slope where it is increasing most) while its length represents the slope of the function at that point. In other words, if you keep following the gradient, you will eventually reach a local maximum!
The gradient can be represented as a vector of multiple partial derivatives. As an example – in 2 dimensions or in terms of a 2-dimensional vector field, the gradient can be written as:
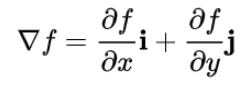
or:

Let’s take an example function provided below:
f(x, y) = 3x2 + 8xy – 3y5
To find the gradient, we first have to find the partial derivatives of this function:
df / dx = 6x + 8
df / dy = 8 – 15y4
The gradient of the above function is therefore:
∇f = ⟨ df/dx , df/dy⟩ = ⟨ 6x + 8, 8 – 15y4 ⟩
Gradients are extremely useful. They’re currently being utilized almost everywhere in the context of machine learning and AI, as well as mathematical optimization / physics / many other domains. Backpropagation (a technique for calculating gradients) enables neural networks to adjust their weights and biases such that they can ‘learn’ and reach their desired end-state. One of the key algorithms used to do this is called gradient descent.
Gradient Descent
Gradient descent is a first-order optimization algorithm which is used to find a local minimum of a function. Using gradient descent, one takes steps proportional to the negative of the gradient (or of the approximate gradient) of the function at the current point. Depending on where you start, the descent converges to the local optimum.
Another intuitive way to think of gradient descent is to imagine the path of a river originating from top of a mountain. The goal of gradient descent is exactly what the river strives to achieve - namely, to reach the bottom most point (at the foothill) climbing down from this mountain.
The algorithm is outlined below:
Define a model depending on W (the parameters of the model).
Define a loss function that quantify the error the model does on the training data.
Compute the gradient of this loss.
Adjust W to minimize the loss by following the direction of the computed gradient.
Repeat until:
Convergence or
The model is good enough
Let’s illustrate how gradient descent works by wring a mini-python script which uses this algorithm in order to reach the function minimum:
import numpy as np
import matplotlib.pyplot as plt
# Hyperparameters
LEARNING_RATE = 0.1
NUM_ITERATIONS = 15
INITIAL_GUESS = -8
# Define the target function to be optimized
def target_function(x):
return x**2 + 5*x + 6
# Define the gradient of the function (the derivative of our target function)
def gradient(x):
return 2*x + 5
# Gradient Descent algorithm
def perform_gradient_descent(learning_rate, num_iterations):
x = INITIAL_GUESS
updates = [x]
for _ in range(num_iterations):
gradient_value = gradient(x)
x = x - ( learning_rate * gradient_value )
updates.append(x)
return updates
# Function used to plot our updates and function
def plot_results(updates):
# Generate x values for the function plot
x_vals = np.linspace(-10, 2, 400)
# Calculate corresponding y values using the target function
y_vals = target_function(x_vals)
# Create a new figure for the plot with a specific size
plt.figure(figsize=(10, 6))
# Plot the function curve
plt.plot(x_vals, y_vals, label='Function Curve')
# Plot the updates made by gradient descent as red points
plt.scatter(updates, target_function(np.array(updates)), color='red', label='Gradient Descent Updates')
# Set labels for the x and y axes
plt.xlabel('x')
plt.ylabel('f(x)')
# Set the title of the plot
plt.title('Gradient Descent Converging to a Local Optimum')
# Display a legend to differentiate between the function curve and updates
plt.legend()
# Display a grid to aid visualization
plt.grid(True)
plt.show()
updates = perform_gradient_descent(LEARNING_RATE, NUM_ITERATIONS)
plot_results(updates)The output we get from running the above script is provided below:

As you can probably see – our script updates our x value from our initial guess (-8) to values which gradually approach our function minimum (-2.5). In order to do this – we simply follow the direction of our gradient down towards our optimum by continuously updating our x value by a subtracting the gradient at each updated x point multiplied by a constant we call the ‘learning rate.’ The learning rate determines the step size we take in order to reach our minimum, and it plays a vital role in machine learning and gradient-based optimization. We won’t dive into too many details in how this parameter is adjusted or needed. Here – we simply wanted to provide an extremely simple demo outlining how the gradient descent algorithm works!
There are many real world applications of gradients. In the study of heat transfer, gradients are essential for understanding how heat flows between objects. In engineering, gradients are used to analyze stresses and strains in materials. They’re also used in computer graphics to create realistic terrain rendering, giving depth and texture to virtual landscapes and are vital in edge detection algorithms which identify object boundaries in images used in object recognition and segmentation. We could keep going. Here – we simply scratched the surface. Hopefully though, readers new to gradients found this brief into overview useful!