
Intuitive and Visual Guide to Transformers and ChatGPT
An intuitive and visual exploration of how transformers and large language models like ChatGPT work.

I wasn’t too happy with many of the explanations of how ChatGPT and large language models worked which I found online. Many of the explanations focus in on ChatGPT being a simple next-word predictor, and after using ChatGPT for quite a few months now to help me with generating and automating all sorts of tasks, I found these explanations quite lacking.
For one, ChatGPT isn’t mediocre at attempting to generate text for the tasks which I told it to generate. In a lot of instances, it was able to generate incredibly elegant code and to fix the issues which came with it when I prompted it to do so – showing that it wasn’t just producing auto-correlated text. In other words, it’s not a simple next-word predictor and it’s in not strictly Bayesian in nature. Noting this, I decided to venture into the world of transformers and large language models and to try to grasp how exactly they performed their magic. To do this, I used the methodology I usually use when I’m confused about a particular topic: the Feynman method.
The Feynman method compromises of trying to pretend to teach a concept you want to learn to a young student who has no familiarity with it. To do this, I usually find source material online and take notes on it. If there’s anything I don’t understand, I find more material to read / watch and I keep taking notes until the concept is clarified. The general goal is to be able to understand the main components of a process from start to finish by 1) breaking them down into a step by step procedure composed of simple components and 2) providing explanations on how the simpler procedures / components work so that anyone reading it can have an intuitive understanding of how the whole thing functions.
Now, writing about ChatGPT isn’t an easy thing to do. To tell you the truth, I got lost quite a bit in my quest to simplify it. For one, Open-AI isn’t … well, ‘open,’ so a lot of the information on how this GPT model works may not be accurate and is extremely hard to verify. Noting this, I still did my best to come up with something which could give others a big-picture view of how it all worked under the hood. After a long 6-month journey into transformers and generative pre-trained models, I decided to make the write-up available here.
If you have no knowledge of neural networks, I would recommend you start off by reading my own introduction available here: Visual Intro to Neural Networks. There’s also lots of material on neural networks available on other sites, so I won’t go into too many details here. Noting this, let’s dive into the world of transformers.
Transformers
Transformers revolutionized the field of natural language processing when they were introduced in 2017. The "Attention is All You Need" paper by Vaswani et al. presented the transformer architecture. It addressed the challenges of modeling long-range dependencies in sequences and achieved breakthroughs in language translation tasks. Following its success in translation, the transformer architecture was further explored and applied to various other NLP tasks, including text summarization and generation. How exactly are transformers different from word-completion tasks performed by most modern software (i.e. like WhatsApp?).
In modern text completion tasks, after each word, you may get a few words suggested to you. For example, if you type “Hello, how” the phone may suggest words such as “are”, or “do.” Of course, if you continue selecting the suggested word in your phone, you’ll quickly find that the message formed by these words makes no sense. If you look at each set of 3 or 4 consecutive words, it may make sense, but these words don’t generate anything with a real meaning. This is because the model used in the app doesn’t carry the overall context of the message. It simply predicts which word is more likely to come up after the last few words are prompted.
Transformers are different. They keep track of a much larger context of what is being written, so the text they generate makes more sense. Although they still technically generate text by predicting one word at a time, there’s much more complexity hidden away within a seemingly simple transformer model. When ‘looking’ at the past data, transformers capture the relationships between different elements in the sequence through something called ‘self-attention’. Self-attention allows the model to weigh the importance of different positions and elements in the input sequence and to capture the context which comes with each prior element.
And how are transformers trained? Well – with a ton of data!! ChatGPT was trained using a huge amount of online data-sets along with an agglomeration of books and articles, and this was just for a phase which we call ‘pre-training.’ To perform fine-tuning, ChatGPT used real world human question and answer data sets and live chat results. This was done in order to tune the model to be able to converse with other human beings rather than simply being able to predict next words within text. Let’s not get ahead of ourselves though. First, we need to go over the general transformer architecture.
The Architecture
Before we dive into the details, let’s take a look at the full transformer architecture diagram outlined in the original paper ‘Attention is All You Need.’

To understand how transformers work, let's break things down and map out the key components and their interactions. We’ll then discuss how these elements relate in terms of the GPT architecture and what new elements have been added in order to make GPT as powerful as it is today.
Tokenization

The transformer takes a sequence of words and transforms them into tokens. For efficiency, GPT-3 actually uses byte-level Byte Pair Encoding (BPE) tokenization. What this means is that "words" in the vocabulary are not full words, but groups of characters (for byte-level BPE, bytes) which occur often in text.
As an example, the text ‘I love reading about transformers’ would be broken up into:

Afterwards, it’s converted into integers which represent unique ids for each token within the text. In the above instance, our 9 tokens would get converted to:
[40, 3021, 5403, 922, 87970, 13]
The above example was taken directly from the OpenAI tokenizer which is available to everyone to experiment with. You can experiment with it yourself using the link below:
https://platform.openai.com/tokenizer
Embeddings
To make tokens more useful to the model, rather than just feeding in the raw numbers, each one is transformed into a numerical representation called an embedding. This representation helps the model understand the meaning and relationships between different elements in the sequence.
For example, the “I” token (represented by token 40) might get converted to the vector [0.2, 0.5, -0.1], the "love" (token 1842) may be mapped to [0.8, 0.3, 0.6], and "movie" (token 3807) might get converted to [0.4, -0.2, 0.9]. Although we use 3 numeric values to represent each word in our example above, the dimensionality (the number of numeric values) present in each word vector could be comprised of any number of values. In the instance of ChatGPT, the resulting vector has a length of 12,288 (with GPT3 having a length of 1,536). You can think of each value within our vector representing some sort of quantifiable property of each word. If two pieces of text are similar, then the numbers in their corresponding vectors are similar to each other. Otherwise, if two pieces of text are different, then the numbers in their corresponding vectors are different.
Even though embeddings are numerical, you can also imagine them geometrically. Imagine a 2-dimensional word-embedding (i.e. each word is converted to a vector of length 2). We can then use a regular graph representation to model. A snapshot of what some sample words in this word-embedding might get mapped to is shown below:

An embedding could also have more dimensional information than simple ‘semantic’ or logical meaning of each individual word. In the case of a much larger embedding (where each word gets sent to a longer vector), the words no longer live in a 2-dimensional plane but in a larger multi-dimensional space. However, even in that large space, we can still keep the representation of words as being close or far away from each other through the measurement of vector similarity: similar words have similar vector values while non-similar ones don’t.
Think of it this way: our brains store many connections in regards to each word which we have in our vocabulary. As an example, the word ‘movie’ could be connected to a whole range of other neurons. Together with a specific date, the word ‘movie’ and the date itself could come up with a more specific movie reference (like ‘gone with the wind’ which we happened to have watched or heard of on that date).
The word ‘movie’ itself has many other connections in regards to what the term actually means and in which context it is used in. This is essentially what our embedding vector above holds. As an example, one numeric value in our vector might encode sentiment (how good we feel about watching movies vs. reading), and another one may hold the movie ‘romance’ factor (is there a love story or stories and to which degree within the flick?). We could store every individual factor within a column in our vector. We could also extend our vector dimension to encode for as many ‘attributes’ for each term within our dictionary as we want!
The embedding layer here essentially maps each term or token within the vocabulary to a more expressive numeric representation!
The embedding represents the data we actually feed into our model. In other words – this is the data element which our encoding / transformer architecture will ‘train’ on (after having the positional encoding added which we discuss below).
Positional Encoding

Since transformers don't inherently understand the order of words in a sequence, positional encodings are used.
For simplicity, let's assume we use a simple positional encoding scheme where each word is assigned a numerical value corresponding to its position in the sentence. In our example, "I" at position 1 might be encoded as [1, 0, 0], "love" at position 2 as [0, 1, 0], and "reading" at position 3 as [0, 0, 1]. The above is an example of one-hot encoding. In one-hot encoding, we use a value of 1 at the positional location where the word or token is located while we 0 out all of the other values.

The actual encoding used in the original paper isn’t one-hot encoding though. The encoding used there uses the cosine and sine functions. By using this encoding, the model captures periodic patterns within our sentences along with the general global positioning information. In other words, not only do we encode the information about each word locally (to capture trends between words), but we also capture the longer acting connections between each word.
To add the positional encoding to a GPT3 model, we would simply add another vector of size 1536 to each one of our word embedding vectors (since the embedding vector size is 1536). The positional embedding is only computed once and re-used for every sentence during training and inference, so a lot is saved in terms of computing cost.
You don’t have to worry too much if you don’t understand the full detail on positional component I outlined above. The important points are that our first 2 steps:
transform our natural language grammar into a vector of numeric values representing the meaning of the word and
encode the position of each word and pass this information along to the next step.
Encoder-Decoder Structure
Transformers typically have two main parts: an encoder and a decoder. In tasks like machine translation, the encoder processes the input sequence, and the decoder generates the output sequence.
Encoder layers


The encoder takes the encoded input sentence and processes it through multiple layers which consist of self-attention and feed-forward neural networks.
Self-attention
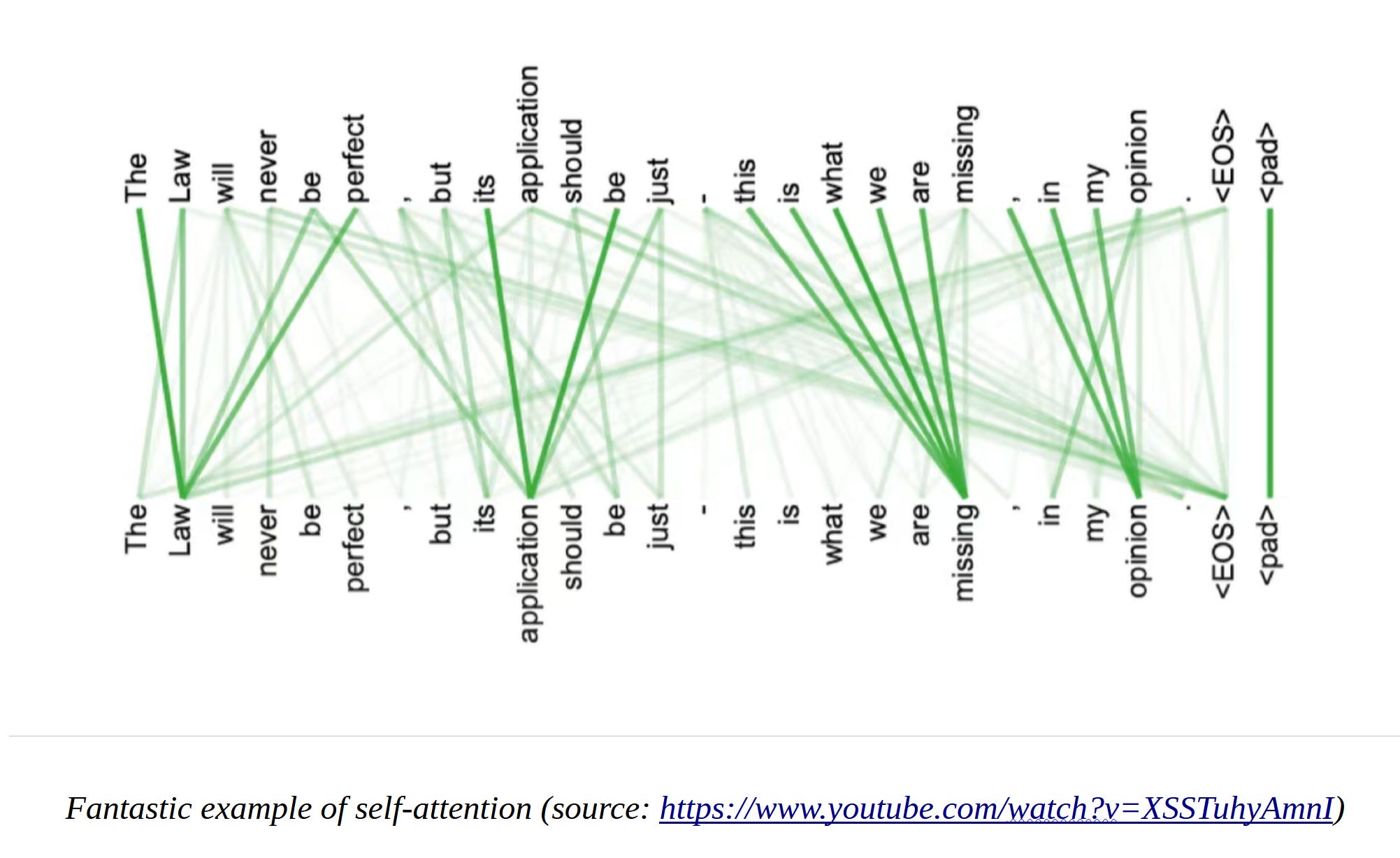
The self-attention mechanism in the encoder is extremely important. It helps the model understand the relationships between different words in the input sentence. In essence, it assigns weights to words based on their relevance to each other. For instance, in our example ‘I love reading’, "love" might have a higher weight with respect to "reading" since it strongly influences the overall meaning of the user's question.
Another great example illustrating this is provided in the example below:
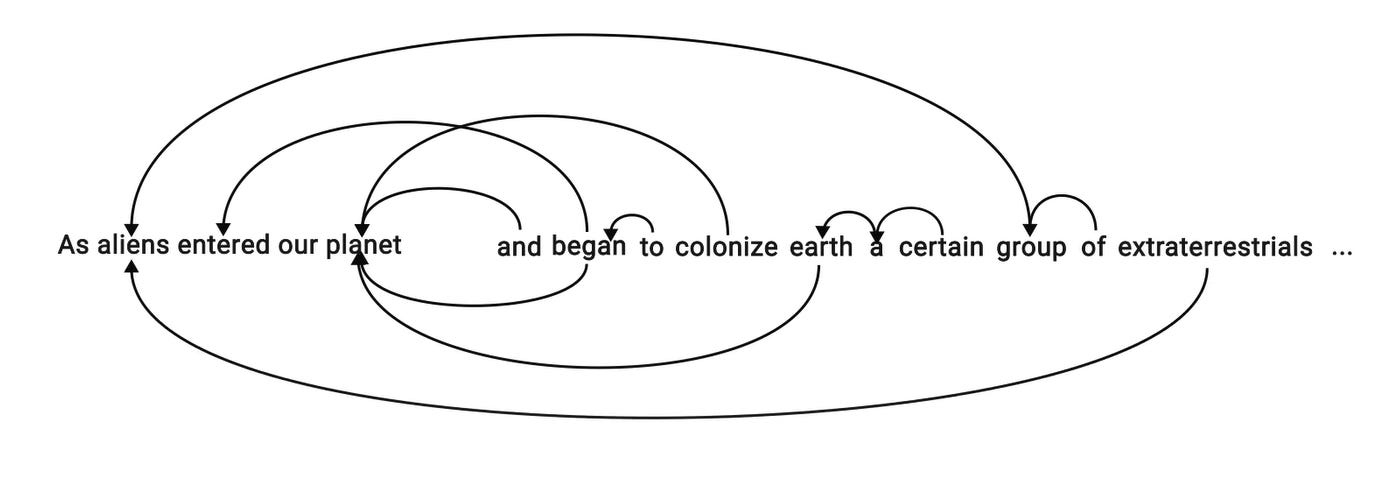
In the above example, your brain automatically infers what each word refers to based on the context given from the previous words which were encountered. As an example, we can immediately see that ‘entered’ refers to ‘aliens’ – as in the aliens entered our planet. When looking at ‘planet’ – we know that this reference refers to ‘earth’ and ‘colonize’. In the same manner, much of the contextual information in every piece of text can easily be figured out by a human being, but the task of figuring it out for a machine is not easy!! This is where self-attention comes to the rescue!
To really understand how this layer works, we need to pay attention to the multi-head attention step outlined within the architecture:

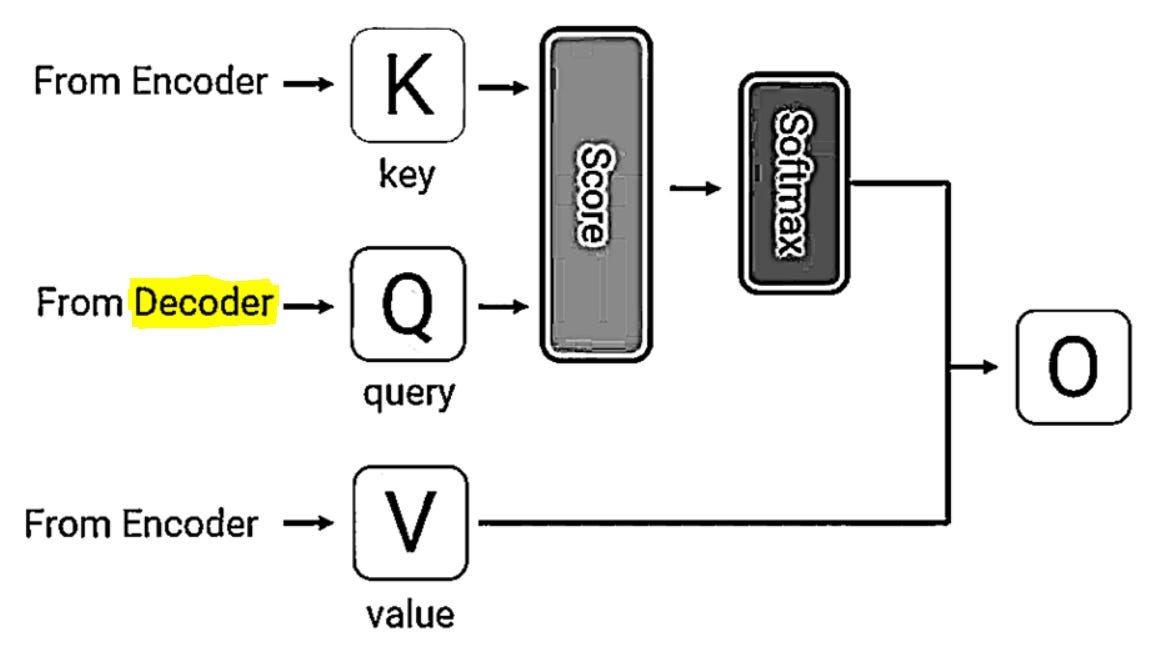
Query, Key and Value Projections
In transformer architectures, the concepts of query, key, and value are essential components of the self-attention mechanism. These vectors are derived from the input sequence, and each word from our input sequence is ‘projected’ on to a separate lower dimensional query(Q), key(K), and value(V) vectors.

The query, key and value vectors don’t have to be smaller than our word vector, but in our example instance above, the word vector is mapped from a 4-dimensional vector to 3 separate 3-dimensional Q, K, and V vectors. The reason this might be done is to save on computational costs. In the original ‘attention is all you need’ paper, the word vector dimensionality was 512 while the query, key and value vectors had a dimension of 64.
After this step is performed, these 3 vectors are then fed into our scaled dot-product attention layer shown below:

Let’s take an example sentence ‘Nick visits Europe’ and see how it breaks down in regards to the query, key, value mapping.
When your eyes see ‘Nick’, your brain looks for the most related word in the rest of the sentence to understand what Nick is referring to (query). Your brain then focuses or attends to the word ‘visit’ (key). This process happens for each word in the sentence as your eyes progress through the sentence. How does a transformer provide a mapping from a query to a key though?
To understand this, we need to focus on the scaled dot product step:

To actually find the mapping of queries to values, a transformer performs the steps outlined below:

The first matrix multiply implements an inquiry system or question-answer system that imitates this brain function using a vector similarity calculation. Think of the matrix multiply as an inquiry system that processes the inquiry: "For the word (query) that your eyes see in the given sentence, what is the most related word (key) in the sentence to understand what the word (query) is about?"
There are multiple ways to calculate the similarity between vectors, and the transformer attention uses a simple dot product.
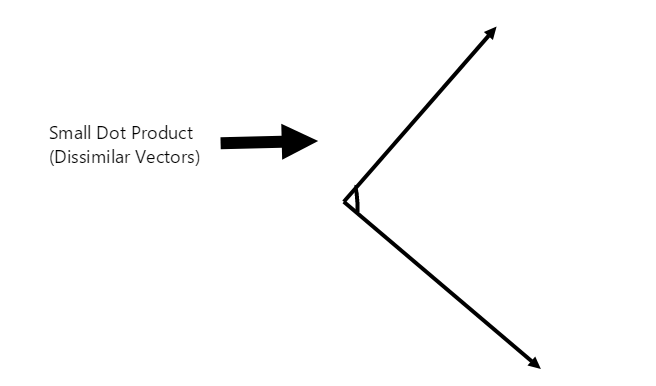
What is a dot product?
If we take the dot product of two vectors v and w, we get a scalar value showing the result of multiplying each of the corresponding vector components of v and w and adding them together:

The larger the dot product value we get between 2 vectors, the higher their similarity:

For each word (query), we compare it to all the keys within our text and find which ones are most similar using the scaled dot product. The higher the value we get for each dot product, the higher the similarity between the query and key. This is the essence of what our attention mechanism is and what our first matrix multiply operation does.
Notice also that I used the term scaled dot product here to describe attention. All this means is that in addition to taking the dot product of the vectors, we also divide the result by the square root of the dimension of the key vectors. As an example, if we used 128 dimensions to describe out key / query / value vectors – here we would simply take the dot product of the key and query vectors and divide this by the square root of 128. This ensures that using a large number of dimensions doesn’t produce extremely large dot products!! Here – we simply want to get a ‘similarity’ between each vector that scales with the number of dimensions we use!
Noting this – let’s get back to our earlier example. Let’s take a look at the probability values that our matrix multiplication might provide:

After obtaining these values, they are scaled and a soft-max layer within the network is then used to normalize the output (such that the probabilities sum to one).

Finally, we get to the last matrix multiply step. This is what results in our value.
Question: What exactly is the difference between each key and each value?
Well, there doesn’t have to be a difference, but if one exists – usually, you can think of the key as a mechanism which captures the sort of information the word represents (i.e. an adjective / noun next to some sort of property within the sentence giving it a specific meaning), while the value maps to the information that the word actually contains. Under the hood, the query, key and value are all just vectors, and a query and a key match if their vectors are similar.
The Matrix (The Data Structure Used to Represent Our Data)
The above captures the essence of what happens in the self-attention step, but if we wanted an illustration of what happens in regards to the computational side, we would get a much better image by focusing in on the matrix mechanics and matrix computations which take place.
Although we started our introduction to attention in terms of vectors, whereby each word from our input was transformed into a multi-dimensional numeric vector, the actual data structure fed into our self-attention system isn’t performed in terms of vector operations. Instead, matrices are used.
A matrix is basically an array of vectors. It provides a convenient way to represent and perform operations on data and mathematical objects in linear algebra. This representation is widely used in machine learning in order to optimize computational steps and processes (along with tensors, which are just higher-dimensional matrices).
The below diagram gives a full view of what happens during self-attention step in a transformer (using matrix mechanics):

I won’t go into the full details here on what exact steps are involved, but I’ve included the full details on the exact matrix mechanics which take place at the end of this post in the appendix section. In essence, we are ‘scaling’ each value projection by a ‘growth’ and ‘shrink’ factor which we realize by computing our query to key attention score and multiplying each value within it to a mapping within our value matrix. The end result is a value matrix scaled by our attention scores!
Add and Norm
After calculating our attention matrix, the original input embedding matrices fed into each layer are added to our output and an additional normalization step is performed:

Addition:

The first step is simple matrix addition. We take our input matrix and add the output of our multi-head attention layer.
Layer Normalization:
This plays a crucial role in stabilizing the learning process, reducing sensitivity to initialization, improving generalization, and handling inputs with different scales. It ensures that the mean activation of each layer is centered around zero and that the variance is approximately one. This helps stabilize the learning process by reducing the impact of variations in input distributions and allows for more efficient gradient propagation during training.
Let’s go through a simplified example to illustrate what normalization does to our input vectors:

In the above instance, we’re given 2 sets of matrices containing a 3-dimensional word embedding. First, we take the average and variance of each matrix:

We then shift and transform each matrix such that the average of each value is 0 while the variance is set to 1:

And that’s it - we’re done!!
Layer normalization was originally used in recurrent neural networks to fix issues regarding batch normalization (another popular normalization methodology) which didn’t work well in natural language processing tasks. We won’t go into too many details here, but wanted mainly to note what the "add and norm" step does. To put it simply, it helps facilitate better gradient propagation and aids in learning.
How can we understand self-attention intuitively?
Most language models prior to ChatGPT were simple statistical models, with one common type being n-gram models. These models focused on predicting the next word in a sequence based on the previous n-1 words.
In other words, these models calculate the probability of each word given its context (the preceding words) and by being trained on a large corpus of text. A simple example of an n-gram model which is given the task of predicting what comes next in the sentence ‘The train of thought’ is shown below:

In our above example, we’re using a 4-gram model. Our training data may contain sentences such as:
"The train of thought is difficult to follow."
"The train of thought can quickly derail."
"The train of thought often leads to creative ideas."
In a real-world scenario, these probabilities would be based on the occurrences of these word sequences in a large and diverse training dataset. In the above instance, if we were to focus in on the most probable word sequence, the 4-gram model would use the word ‘is.’ We would thus feed in ‘train of thought is’ as our next sequence and use a similar approach in our next word prediction task.
You can probably see that n-gram models tend to be very simple and have issues in ‘generalizing’ word prediction tasks. They consider only a limited number of preceding words and have no conception of the meaning and context behind each word that’s encountered.
How do transformers address this issue?
As we already outlined – transformers don’t simply take the statistical distribution of words which come after a sample block of text. Transformers ‘transform’ each word into a very large unique embedding vector which may contain more than 1,000 numeric values for each word within our vocabulary. We can think of these representations as representing a ‘neuron bundle’ which is supposed to encode various properties of each word. After performing this step – we reduce the dimensions of this vector and feed it into our self-attention layer which:
Takes each word within our block of text and performs a dot-product similarity score between each neighboring word present within the context window.
Scales each of the neighboring words within our context and adds them together to come up with a new ‘encoding’ for our vocabulary word which now contains the context information behind each word.
As an example, in the ‘the train of thought’ sentence, the word train would in essence be processed in the following way:
The relationship between ‘train’ and its neighbors (‘the’, ‘of’, ‘thought’) would be computed using a dot-product similarity score.
The similarity scores would be used to ‘scale’ each of the neighboring word value vectors.
The scaled value vectors are all added together.
A very simple high-level diagram capturing this is provided below:

The above ensures that our transformer model takes context in the word encoding!! As an example, when we usually think of the word train, we tend to think of its noun representation (i.e. a connected series of railroad cars lead by a locomotive), but in our example context – the word train refers to a completely different meaning! In our above context, train is used as a metaphor. It’s used to describe a sequence or series of events or actions.
The complexity doesn’t end there though. Train has other meanings as well – like "to train" means to instruct, guide, or educate someone or something. In other instances, we might be referring to training in the context of physical exercise! In other words, we must take context into account!! The word in isolation in other words cannot reveal the meaning behind it, so we must ensure to encode all of the relevant information! Humans do this naturally, but to do it within a machine learning model, a transformer uses the sequence of steps which we outlined earlier. By scaling the relationships and taking the dot product relations, we are ensuring that the context within each word is included in our model. This step within a transformer model is in essence what we call self-attention!
Multi-Head Attention
The complexity doesn’t end here. To encode each word and its context, we don’t simply apply one transformer layer. To fully perform our encoding, the above process is done 96 times (or more) with different query, key & values scores and the results are added together. This is what we refer to as multi-head attention! You can think of the different layers as being different ‘image filters’ for each word. We’re applying different filters and paying attention to different facets of each block of text which we’re processing. This ensures that we have a very thorough representation of each word and its context prior to moving on to our next steps, which employ back-propagation to train our model.
Feed-forward neural network

After self-attention, the encoded representations of the words pass through a feed-forward neural network. An example image showing a fully connected feed-forward neural network is provided below for reference:

The neural network here is responsible for learning how to perform the task which the transformer is training to perform. A large neural network takes the encoded language and context that’s fed in attempts to map it to the appropriate training data. If the output of the network matches the final result, the network stays the same. If it results in the wrong value - backpropagation is applied and the network weights are adjusted. The network then has a higher chance of producing the correct result the next time the same language data is applied.
GPT does not contain an encoder, so we are going to skip over the encoder neural network details here. We’ll address what these feed-forward models do more thoroughly in our decoder section.
Decoder Layers
The decoder, similar to the encoder, has multiple steps to perform. . Think of it this way: you’re paying a card game and the job in this game is to translate a sentence in one language to a sentence in another one. Let’s assume that we’re looking to perform English to French translation. You pick a random card and attempt to perform the translation by writing down what you believe is the correct French equivalent. After writing down your guess – you then take a look and compare it to the correct answer and adjust the neural-network weights based on the result. This is the gist of what our decoder here does. In terms of how this translates to GPT though, the training process is a bit different. GPT isn’t attempting to perform translations from one language to the next. In a GPT pre-training step, we are attempting to guess the next word in our input based on what we were fed in from a prior context. We already went through some examples when we discussed our encoding layer, but let’s go through another one just to illustrate how our training would proceed.
Let’s assume we are given the input:
“The problem with quotes on the internet is that they are often …”
Here, our task would be to guess the next word. We guess the next word. Based on our answer, we do what we did in the instance for translation: if it is the correct guess, our weights stay the same. If we guess wrong, we take a look at the correct answer and we adjust based on what we see. In the instance above, the correct completion sequence might be “often” followed by “wrong.”
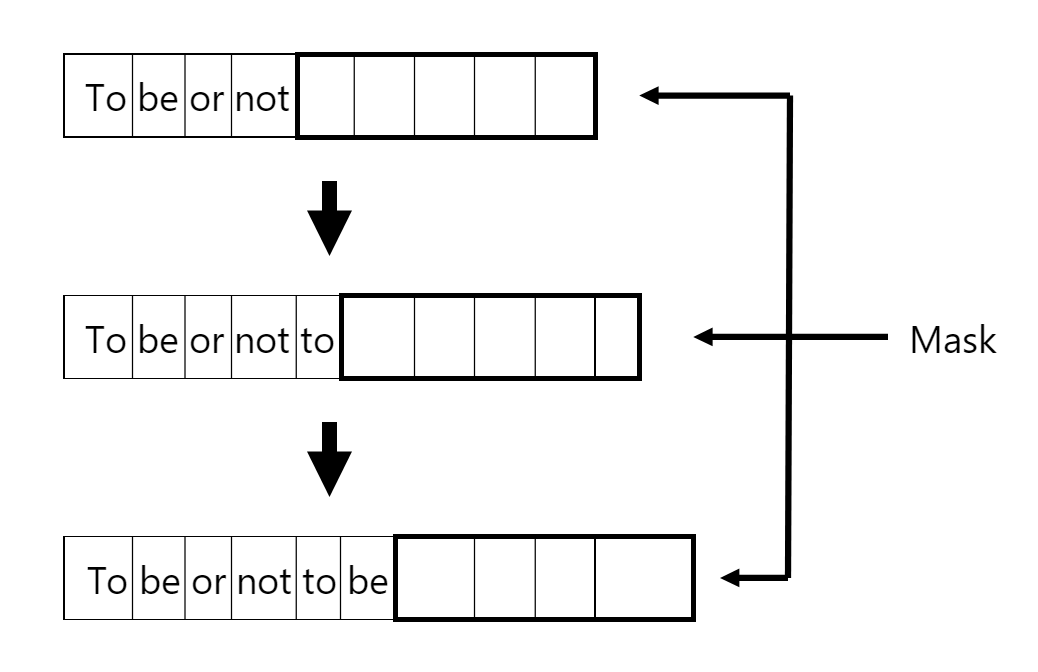
One primary difference between the encoder and decoder blocks is that while the encoder can attend to all of the elements in the sequence to calculate the attention scores, the decoder is limited to only being able to use the previous elements. Instead of being fed in the whole input to output mapping, a mask is applied to the input. The decoder ‘guesses’ what the correct output is and the mask is then removed on a word-by-word basis. The output is compared to the unmasked input and our weights are adjusted to account for training the decoder to ‘guess’ the correct and appropriate words.
Of course, the above just gives an outline of what happens in this layer. Let’s once again go through the architecture mapped out in the ‘Attention is All You Need’ paper and discuss what happens during each training stage in the decoder block.
An entire image of a decoder is presented below:

Let’s go through and cover what each block does one by one.
Output Embedding and Positional Encoding

This step is similar to what we outlined in our encoder model, so we’ll once again summarize what happens here: in essence, our words are mapped to numeric vectors and the positions of each word is encoded using sine and cosine functions.
Masked Multi-Head Attention
This is similar to our self-attention layer which we over-viewed when we went through our encoder – with the exception of adding in masking.
Masking
For this step, we go through the procedure of mapping each word or token to 3 vectors representing the query (Q), key (K) and value (V) for each term in our sequence. We then perform the attention steps similar to the ones we outlined in our encoder with the added masking layer:
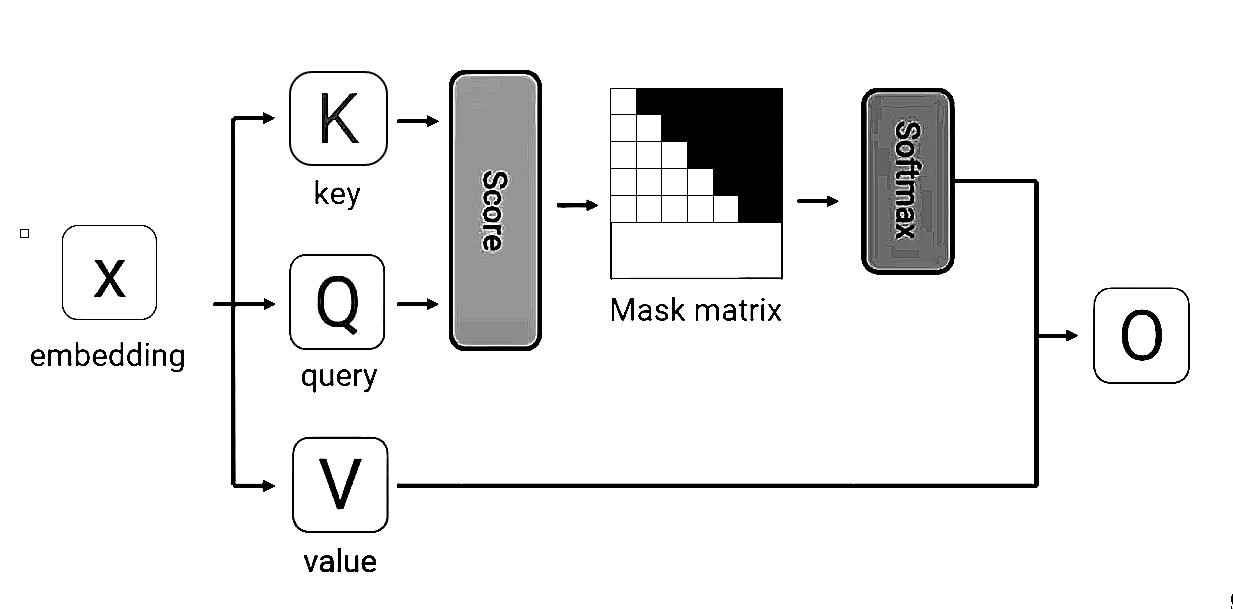
To actually employ masking, a mask-matrix is used. A mask-matrix is an upper triangular matrix where all of the entries above its main diagonal are set to minus infinity:
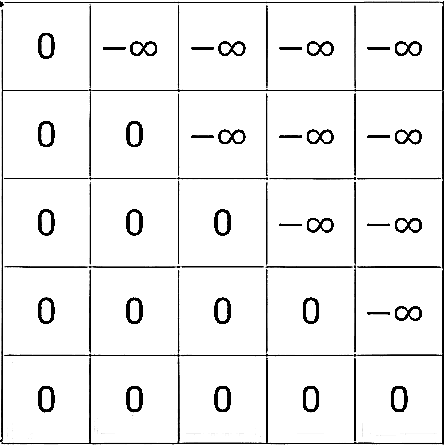
This matrix is added to our query-key ‘score’ matrix (which holds our computed ‘similarity’ values between each query and key) and it performs the masking step by ensuring that all of the look-ahead values within our word sequence are ignored. It does this through the negative infinity addition: each term which could be used as a look-ahead within our sequence is added to negative infinity (which produces negative infinity) and all of these terms are fed into the soft-max layer to produce next-word probability values set to 0:
Multi-head attention
This was already covered in the encoder architecture, but we’ll once again cover it again to make sure we understand what’s going on. The ‘multi-head’ term simply means that our input is mapped to different Query, Key and Value vectors. The masking and similarity scores are computed for each one and the results are added together and projected back to an appropriate dimensional representation to capture the output of each separate head.
Second Multi-Head Attention Step
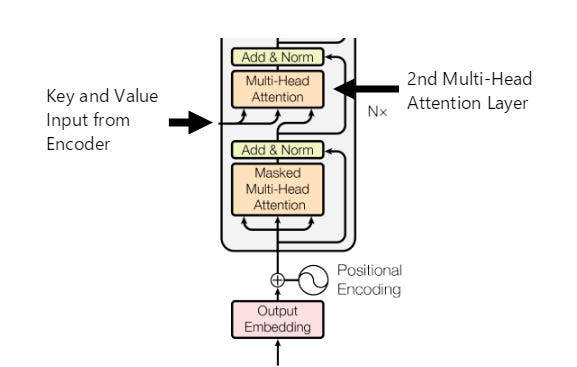
Here, we once again apply self-attention, but instead of using input strictly from either our decoder or encoder, we mix things up. Our decoder feeds in a masked query while the encoder feeds in the key and value vectors:
As we already know – the query and key vectors (or matrices to be exact) are used to compute our similarity scores. In this instance, the query matrix containing our masked sequence self-attention scores are used to find mappings and similarities to our non-masked key values which we computed in our encoder. An encoder-decoder transformer does this in order to properly map one representation to the next: the decoder query is used and it’s mapped to the encoder key / value which contains our translated mappings. As an example, in English to French translation, the decoder would contain the masked French translation data while the encoder would feed in the query and key English mappings. For decoder-only transformers like ChatGPT – this step isn’t needed at all, so using different mappings from 2 different data-sources isn’t necessary. In the instance of large language models, we can simply use the masked self-attention as the default to encode our context since we aren’t attempting to map one neural representation to another one. Here - we’re simply attempting to guess the next word. Masking enables this for us without needing a separate encoding step.
Key Differences Between Encoder-Decoder and Decoder-Only Models
To avoid any confusion, let’s summarize the key differences between encoder-decoder models (used in translation tasks) versus decoder-only models (used for text-generation):
Encoder-Decoder Models:
Two distinct phases: encoding and decoding.
The encoder compresses the input sequence into a context vector, which is then used by the decoder to generate the output sequence.
Separate mechanisms for understanding and generating sequences, allowing for better separation of concerns.
Often used for tasks like language translation, where the input and output sequences may have different lengths.
Decoder-Only Models:
No separate encoding phase; the decoder processes the input sequence directly.
The model handles both understanding the input and generating the output simultaneously.
Typically used in tasks where the input and output sequences are of similar lengths or where there's no clear separation between encoding and decoding phases, such as language modeling or text generation.
While both models serve the purpose of sequence-to-sequence tasks, they differ in how they handle the processing of input sequences and the generation of output sequences. The encoder-decoder model splits these tasks into separate phases while the decoder-only model integrates them into a single step.
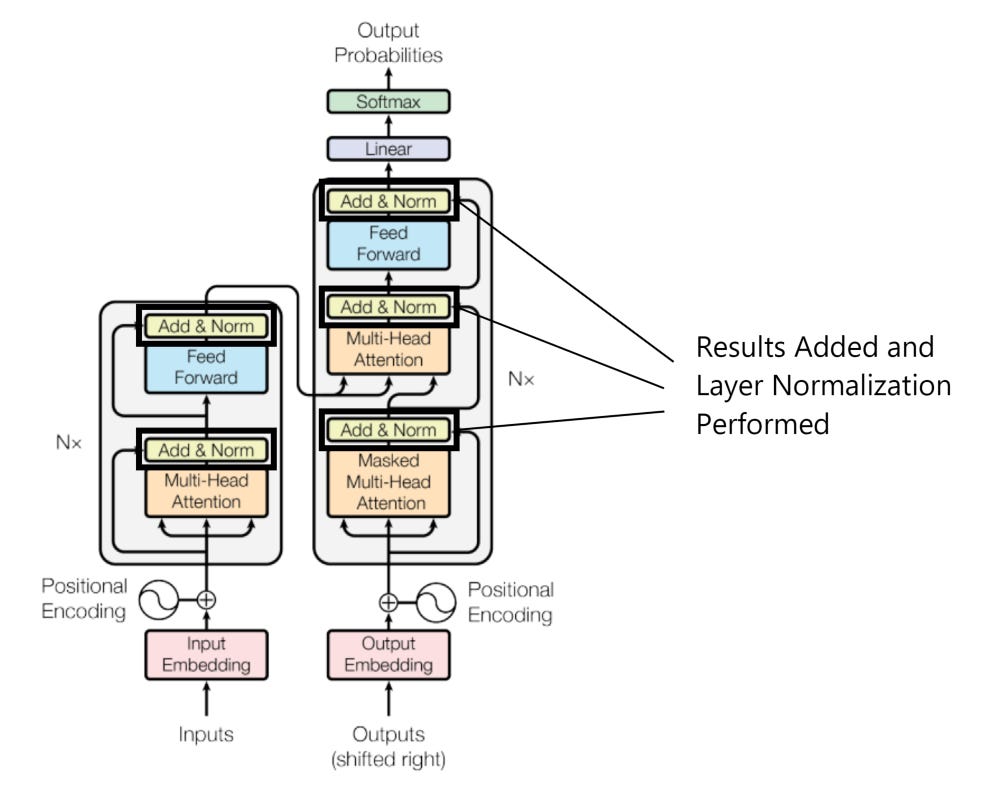
Addition and Layer Normalization
Once again, we add our results together and we use layer normalization after each stage in order to make gradient propagation easier and in order to prevent our model from over-fitting the data set:
Noting this, let’s move on to explaining the next phase – the most important phase within out transformer model, which is the feed-forward neural network. This is the key ingredient in making the whole model work.
Second Feed-Forward Neural Network
This is where the transformer model adjusts its weights. The masked layers which we outlined in the previous steps attempts to predict the next word in the sequence, and this layer simply looks at the discrepancies between the prediction and the real output and uses this information to adjust the feed-forward weights in order to minimize the error.
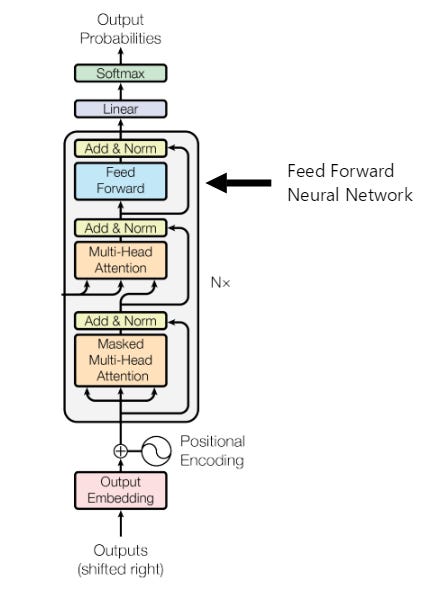
This network is responsible for adjusting our neuron weights based on which next-word ‘guesses’ are correct and which ones are wrong. Once again – we have both the input and output. In relation to GPT: we are given text and our job is to try to predict next-word sequences within our text based on the input ‘query’ or ‘data’ which we are given. All next word pairs within a sequence are masked to try to guess the output, and when a guess is made, the masked next word is revealed and compared to our guess. The feed-forward layer then adjusts our weights to account for any negative or positive feedback within our network.
How the Feed-Forward Model Works
Neural networks are layers of ‘functions’ or ‘neurons’ which serve as function approximators. In the instance of a very simple transformer network, the multi-layered perceptron only has one hidden layer, albeit this layer is extremely large and has many hidden neurons:

With enough hidden neurons, shallow neural networks can approximate any continuous function to arbitrary precision. In the instance of the original transformer architecture, the hidden layer could be made up of around ~48,000 neurons and the ReLU activation function is used (which has the merit of being easily interpretable).

When we use ReLU activations within a neural network, it divides the input space into different regions. These regions are simple, regular shapes called convex polygons. Each ReLU neuron in the hidden layer is a participant in defining these regions via the production of hyperplanes, and a hyperplane is like a decision boundary that helps the network separate different parts of the input space. Essentially, the ReLU activation function helps the network define boundaries in the input space that determine which neuron is activated for different input values.

ReLU activations allows neural networks to capture non-linear relationships and complex decision boundaries in the data, which is essential for learning and representing intricate patterns and structures in tasks like natural language processing, image recognition, and many other complex processing tasks.
Now – the activation function for GPT isn’t ReLU but something very close to it. The actual activation function is GELU (Gaussian Error Linear Unit). The GELU function is a smooth approximation of the rectifier (ReLU) function. It's defined as follows:


Some advantages of using GELU over RELU are provided below:
Unlike ReLU, GELU is a smooth function. It means it has a well-defined derivative everywhere, including at the point where the input is zero. This smoothness can be advantageous during training, especially when dealing with optimization algorithms that rely on derivatives.
The GELU function has a non-zero mean, which can be beneficial in certain contexts. This helps to maintain non-zero activations in the network, potentially addressing the problem where neurons can become inactive during training.
GELU has been found to enhance the representation power of the model. The smoothness and non-linearity introduced by GELU can contribute to capturing more complex patterns in the data.
Empirical evidence suggests that using GELU as an activation function can lead to better performance in certain tasks compared to ReLU. This improvement is task-dependent, but it has been observed in practice.
This step is in essence where our model ‘learns’ how to excel at generating language. It enhances the representation of each word by introducing non-linearity and capturing higher-order interactions between the input features. It then uses these enhancements to ‘train’ on the masked data which is fed into it.
More Intuition Behind the Feed-Forward Network
When I initially used ChatGPT, my thoughts were that OpenAI had a lot more going on ‘behind the scenes’ in its decoder-only transformer model than just simple scaling up of the transformer model and throwing in a ton of data at it. After going through other large-language models and listening to a few interviews done by its founder(s) though – my perception completely changed. The general impression I have now is that ChatGPT doesn’t use any added ‘magic’ or algorithmic complexity which differs from other language models out there. In other words, although OpenAI may have found a few optimization techniques which make their transformer models more efficient to pre-train and tune (as well as having access to a larger volume and high-quality tuning data) – OpenAI may not have a ‘secret ingredient’ which makes its models flourish. In other words, there is no ‘secret sauce’ which makes their large model generalize better than other models out there.
I’m now in the camp that a huge neural network with many parameters are a lot more capable of ‘generalizing’ information and capturing higher-order textual relations than I ever thought possible. Through the simple magic of deep learning, GPT might be capable of capturing patterns and complicated relationships through 2 simple methodologies:
Scale: Make the feed-forward network a huge fully connected neural net with many parameters (along with many layers – albeit transformer models may simply have one layer which is easy to tune).
Large Data Set(s): Feed in a lot of data into the network (we’re talking about all of the internet data along with text books and other word text). The data set which GPT-3 uses is provided below:
You may have the impression that a simple architecture where you simply scale up a decoder-only model and add huge feed-forward layers would not result in something like ChatGPT, but you would be wrong. Other LLM models are currently being trained and are getting closer to generating the results that ChatGPT generates, albeit all of them are not quite there. Some huge models ranked by their ‘power’ are provided below:

A great image which also captures some of the capabilities achieved by different LLMs is also shown in the image below:

Lex Friedman did a great interview with the co-founder and chief scientist at OpenAI Ilya Sutskever in 2020 which does a great job in highlighting some key insights in the magic of deep neural networks and their role in LLMs / ChatGPT which I decided to highlight and provide below.
Ilya Sutskever: “The most beautiful thing about deep learning is that it actually works. And I mean it; because you got these ideas, you've got a little neural network, you've got the back propagation algorithm. And then you've got some theories as to, you know, this is kind of like the brain, so maybe if you make it large … if you make the neural network large and you trained in a lot of data, then it will … do the same function of the brain does, and it turns out to be true, it’s crazy!”
Ilya Sutskever: “Yeah, let's make a big neural network. Let's train is and it's going to work much better than anything before it. And it will, in fact, continue to get better and make it larger. And it turns out to be true. That's amazing. When a theory is validated with this, you know, it's not a mathematical theory. It's more of a biological theory almost.”
Ilya on how LLMs / neural nets may capture higher-level information within text:
Ilya Sutskever: So the history is really, you know, fairly long at least and the thing that started, the thing that changed the trajectory of neural networks and language is the thing that changed the trajectory of all deep learning and that's data and compute. So suddenly you move from small language models, which learn a little bit, and with language models in particular, there's a very clear explanation for why they need to be large to be good, because they're trying to predict the next word. So when you don't know anything, you'll notice very, very broad strokes, surface level patterns, like sometimes there are characters and there is a space between those characters. You'll notice this pattern and you'll notice that sometimes there is a comma and then the next character is a capital letter. You'll notice that pattern. Eventually you may start to notice that there are certain words occur often. You may notice that spellings are a thing. You may notice syntax. And when you get really good at all these, you start to notice the semantics. You start to notice the facts. But for that to happen, the language model needs to be larger.
Lex Friedman: So that's, let's linger on that, because that's where you and Noam Chomsky disagree. So you think we're actually taking incremental steps, a sort of larger network, larger compute will be able to get to the semantics, to be able to understand language without what Noam likes to sort of think of as a fundamental understandings of the structure of language, like imposing your theory of language onto the learning mechanism. So you're saying the learning, you can learn from raw data, the mechanism that underlies language.
Ilya Sutskever: Well, I think it's pretty likely, but I also want to say that I don't really know precisely what Chomsky means when he talks about ... You said something about imposing your structural language. I'm not 100% sure what he means, but empirically it seems that when you inspect those larger language models, they exhibit signs of understanding the semantics whereas the smaller language models do not. We've seen that a few years ago when we did work on the sentiment neuron. We trained a small, you know, smallish LSTM to predict the next character in Amazon reviews. And we noticed that when you increase the size of the LSTM from 500 LSTM cells to 4,000 LSTM cells, then one of the neurons starts to represent the sentiment of the article, sorry, of the review. Now, why is that? Sentiment is a pretty semantic attribute. It's not a syntactic attribute.
Lex Friedman: And for people who might not know, I don't know if that's a standard term, but sentiment is whether it's a positive or a negative review.
Ilya Sutskever: That's right. Is the person happy with something or is the person unhappy with something? And so here we had very clear evidence that a small neural net does not capture sentiment while a large neural net does. And why is that? Well, our theory is that at some point you run out of syntax to model, you gotta start to focus on something else.
Lex Friedman: And with size, you quickly run out of syntax to model and then you really start to focus on the semantics would be the idea.
Ilya Sutskever: That's right. And so I don't wanna imply that our models have complete semantic understanding because that's not true, but they definitely are showing signs of semantic understanding, partial semantic understanding, but the smaller models do not show those signs.
Lex Friedman: Can you take a step back and say, what is GPT2, which is one of the big language models that was the conversation changer in the past couple of years?
Ilya Sutskever: Yeah, so GPT2 is a transformer with one and a half billion parameters that was trained on about 40 billion tokens of text which were obtained from web pages that were linked to from Reddit articles with more than three votes.
Lex Friedman: And what's a transformer?
Ilya Sutskever: The transformer, it's the most important advance in neural network architectures in recent history.
Lex Friedman: What is attention maybe too? Cause I think that's an interesting idea, not necessarily sort of technically speaking, but the idea of attention versus maybe what recurrent neural networks represent.
Ilya Sutskever: Yeah, so the thing is the transformer is a combination of multiple ideas simultaneously of which attention is one.
Lex Friedman: Do you think attention is the key?
Ilya Sutskever: No, it's a key, but it's not the key. The transformer is successful because it is the simultaneous combination of multiple ideas. And if you were to remove either idea, it would be much less successful. So the transformer uses a lot of attention, but attention existed for a few years. So that can't be the main innovation. The transformer is designed in such a way that it runs really fast on the GPU. And that makes a huge amount of difference. This is one thing. The second thing is that transformer is not recurrent. And that is really important too, because it is more shallow and therefore much easier to optimize. So in other words, it uses attention, it is a really great fit to the GPU and it is not recurrent, so therefore less deep and easier to optimize. And the combination of those factors make it successful.
In other words – Ilya tells us that the ‘secret’ towards getting GPT to do what it does is through making it bigger, giving it more data and letting the large shallow neural network figure out the key contextual relationships which it needs to ‘figure’ out in order to be great at generating text.
Yes, but can we get a better intuitive understanding of what each layer encodes?
To do this, we can reference the paper titled Transformer Feed-Forward Layers Are Key-Value Memories
The paper goes on to explain that each key in a transformer corresponds to specific text patterns found in the training examples, while each value influences the distribution of the possible output words. They also found that lower layers (self-attention) of the model capture simple and shallow patterns while the higher layers (feed-forward) capture more semantic / complex ones. These feed-forward layers in other words seem to be responsible for much of the amazing performance in transformer models.
They attempt to also show that the output of a feed-forward layer is a combination of its memories, which are further refined across the model's layers using residual connections resulting in the final distribution of likely output words. A great summary image provided in the paper is shown below:
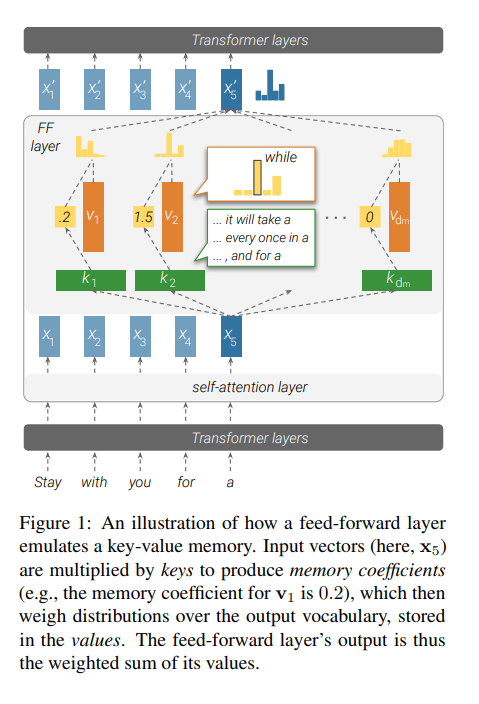
Some great examples illustrating the difference between shallow and semantic patterns are also provided:

Image from the paper which demonstrates that neurons from lower layers capture shallow patterns while higher layers capture more semantic ones:

A paper which hints that the feed-forward layers function more than just ‘key-value memories’ is available here: Neurons in Large Language Models: Dead, N-gram, Positional.
Some key highlights:
In the early part of the network, many neurons are inactive, meaning they don't activate on a wide range of data (more than 70% in some layers of the 66 billion parameter model).
The active neurons are mainly reserved for detecting specific features, like tokens and n-grams.
Interestingly, these active neurons not only suggest the next token but also focus on removing information about the current input, which is a novel finding.
As the model size increases, it becomes more sparse, meaning it has more inactive neurons and token detectors.
Some neurons are position-dependent, meaning they activate or deactivate based on position rather than textual data (mostly in smaller large language models).
Smaller models have neurons indicating position ranges more explicitly, while larger models do this in a less clear manner.
Similarly to the key-value paper, they show that early layers encode largely shallow lexical patterns while later layers encode high-level semantics.

Since the number of possible shallow patterns is not large and potentially, enumerable, in the early layers, the model can assign dedicated neurons to some features. The more neurons that are available to the model the easier this is to do and so larger models tend to be more sparse. In addition to this, smaller models rely substantially on oscillatory neurons: this is the most frequent type of positional neurons for models smaller than 6.7b of parameters. In combination with many less than/greater than neurons, the model is able to derive token's absolute position rather accurately. Interestingly, larger models do not have oscillatory neurons and rely on more generic patterns shown with red- and green-colored circles:

I won’t dive into all the details here, but you can find a great overview and summary of these results here:
https://lena-voita.github.io/posts/neurons_in_llms_dead_ngram_positional.html
You can think of these layers of key-value associative memories which we brought up in some of our earlier examples. They not only capture simple patterns within sentences, but also capture more complex relationships and serve to predict contextual information within certain bounded context that allow prediction to be more accurate.
Let’s take an example of the following sentence:
‘Mike and I were at the dock, and after a few beers, we got tipsy and we almost …’
Now, as a human being – you might say that there are a lot of possibilities here in our word completion task. The context is that 2 individuals were at the dock and had a bit too much to drink, so some of the possibilities here may involve 1) knocking over the boat or 2) slipping and falling or 3) falling into the water or etc...Now, the details here aren’t important. What’s important here is the exact context: we have certain things which we know and which we humans associate with certain outcomes. We use our memories in order to come to these associations. To try to predict what comes next, we take the most probable outcomes which come to our mind and we might try to guess that ‘Mike’ and his friend were involved in some sort of incident.
In this same manner, the feed-forward layer takes many training examples and develops a context that comes with each input. These contexts are captured and the patterns within them are also mapped and captured by these layers. In essence, they serve similarly to auto-associative memories which aid us in word-completion tasks and which make transformer models so powerful!
Temperature
As you may already know, the output from a human-being is not deterministic. We may for example provide different answers to the same question based on 1) the context of our conversation 2) the context and tone of our previous conversations and 3) simple randomness introduced though the complexity of the human brain and the non-deterministic and chaotic manner in which it sometimes processes information in.
To introduce this ‘randomness’ into our model, a parameter called the temperature is used, and it allows us to tune the randomness within our LLM or GPT model. In other words – the higher the temperature setting, the more randomness we introduce in our next word prediction task. Our model doesn’t simply pick the word with the top probability value which our feed-forward network points to. Instead, our model randomly samples from the top-K values generated by our next-word prediction output. K may be an integer parameter which is either hard-coded into our network or may be generated based on our temperature value. Either way - this ensures that we have some randomness and variation in our output — and important component in making the output more interesting.
GPT-3
In our discussion above, we mainly focused on outlining the transformer architecture and outlining the components in decoder-only transformer pre-training. We need to go further in order to understand more-advanced and human-centric models like ChatGPT.
Let’s summarize what we’ve outlined so far. A decoder-only transformer optimized for next-word prediction:
Converts the sequence of text into input tokens.
Maps the input tokens to much larger multi-dimensional embedding vectors which capture the 1) meaning and 2) positional encoding information for each token.
Uses multi-head attention to capture meaning and relationship information between the embedding information along with the specific word context.
Uses masked attention in order to produce a set of probabilities for the next word to generate.
Checks the accuracy of its guess once it’s produced: a shallow but large feed-forward neural network is used to compare the next-word guess to the actual output. After comparing the results, the network weights are adjusted to capture the information it needs in order for it to do better next time.
It continues on with attempting to generate the next word, incorporating context from the preceding words and continuing on with the above training process.
That’s it!! That’s all there is to it!!
Ha! Well … not really! Sorry for the bad news, but that only refers to the training needed in order to make the base model work! Further refinements need to be made in order to generate an agent which can have conversations with humans. To do this, we need to go through more steps of fine-tuning our base model, but the large majority of our hardware utilization is spent on this base model. It takes a lot of energy to train it!
The main key is that 1) GPT has a lot of data and compute to work with and 2) the sequence length (and thus the context) it has to work with is 2048 tokens long. The total batch size is 3.2 million tokens. There are 96 heads in the self-attention layers, and the value, query, and key dimension is 128. It is trained with 300 billion tokens and contains 175 billion parameters. We’re talking about a massive amount of data to train with here.

You would think that throwing in a large amount of hardware and data would produce the results we want – but we are not done. The job of a GPT model isn’t to simply predict the next token in a sample of text input. Its job is to simulate and provide a live human-centered assistant which is able to answer and generate text based on a wide range of inquiries!
To put it simply: everything we went over in the above transformer discussion only involved the transformer model pre-training and next-word prediction. If we were to use our current next-word prediction model, it wouldn’t do a very good job conversing with a human being. To adjust our model to respond to human input and feedback, we need to go to the next step which is called fine-tuning.
Fine-Tuning
During this step, our large language model (or ChatGPT) generates multiple responses for numerous prompts and human reviewers rank them based on their quality. The model which is generated from this feedback is called the assistant model.
The training data used for this model is completely different than the unranked data our in the base model. Here, we have real human centered and labeled question and answer data sets. In other words, instead of using our raw internet or book data, real humans are asked to read questions and provide their own ‘ideal’ answers. This data-set is then fed into our assistant model and used to produce the next stage of training, which once again asks human participants to provide a ‘rank’ for each set of answers produced by the GPT model. These rankings are used to furthermore train another model called the reward model.
The main reason for the reward model is to avoid the cost of needing real-time human feedback for every response. Instead of asking humans to rank the responses individually, this reward model is trained to predict how humans would rank it. To do this, a small fraction of the output generated from the training process is shared with human reviewers. This data is utilized to further train the reward model using heuristics (such as reward model uncertainty) to guesstimate the quality of the model output.
If you want the full details, you can find them in the following paper: Training language models to follow instructions with human feedback.
A great diagram which provides a summary of fine tuning is provided below:

Once again, although GPT-3 already demonstrated the ability to follow natural language instructions / prompts just after pre-training, these instructions typically needed to be carefully worded in order for it to perform well. In order for us to achieve the next breakthrough in getting our model to perform well on human data, we needed to do fine-tuning which got our model to 1) work with higher quality data to judge and asses how high the quality of its output was and 2) develop further models which were involved in ranking different answers to the training data. These let our model develop and ‘instinct’ on how good each result was.
You can think of this as intuitively conversing with different humans and using their response to judge the appropriateness of your feedback. Of course – generative pre-trained models don’t have access to this type of data, so we simply ‘simulate’ this process through fine-tuning and by having a separate reward model to perform the task!! This reward model can be thought of as representing the natural ‘human instinct’ which the model can use, and it uses it to rank and judge the quality of its own responses.
Few-Shot Learning
Fine-tuning a large-language model doesn’t need to involve any human feedback in order for it to achieve outstanding results. Instead, feeding in a few examples into each prompt can give an LLM the contextual information it needs in order to ‘generalize’ and solve a task.
You can find more details in a paper called: Language Models are Few-Shot Learners.
Some key highlights from the paper are provided below:
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions – something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art finetuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
In other words – the authors of the paper found that large language models develop a broad set of skills and pattern recognition abilities from n-shot learning – where n represents an integer and where the task performance increases as n increases (i.e. more examples are provided). It then uses these abilities at inference time to adapt to or recognize tasks and can use this info in making its prompt responses more accurate without having to do any fine-tuning and without having to update its feed-forward model weights.
This ability to extract patterns from examples is called ‘in-context’ learning and some examples of sequences fed into the input are provided below:

In the above example, we can see that when prompted to do arithmetic / addition, the model learns how to output the correct results; when prompted with misspelled words followed by their correct spelling, the model learns to correctly output spelling corrections – and when prompted to provide translations (from English to French) – the model recognizes this pattern as well and correctly outputs the French translation when prompted with an English word.
A diagram which shows that the more examples we use – the better the model can generalize is provided below:

And a simple diagram showing an example of zero-shot, one-shot and few-shot learning vs. traditional fine-tuning:

Key quote:
GPT-3 also displays one-shot and few-shot proficiency at tasks designed to test rapid adaption or on-the-fly reasoning, which include unscrambling words, performing arithmetic, and using novel words in a sentence after seeing them defined only once. We also show that in the few-shot setting, GPT-3 can generate synthetic news articles which human evaluators have difficulty distinguishing from human-generated articles.
In other words – GPT3 can extract the ‘meta’ information from sequences and apply them to improving its set of outputs without having to do any backpropagation!
How exactly the authors of the paper got GPT to recognize ‘meta-patterns’ isn’t really revealed, and we’re left with the notion that simply scaling up the models leads to them being able to extract ‘higher order’ meta information from text which is fed in. From the input text, the model is able to recognize patterns and use these patterns to accurately produce the desired output!
The LLMs trained by the authors also use sparse attention and sparse transformers. These are different from the regular attention / transformer mechanism we outlined earlier. These models introduce a mechanism which focuses in on specific parts of the input sequence rather than using the whole context window / sequence. The authors of the paper here note that sparse transformers can ‘ achieve state-of-the-art compression and generation of natural language, raw audio, and natural images. The simplicity of the architecture leads us to believe it may be useful for many problems of interest.’ In other words – this sparse architecture may be useful in helping the model perform information compression as well as meta-learning, although this is more-of my interpretation of the paper rather than something that’s outlined by the authors.
A great diagram which also illustrates the key difference between normal transformers and ones which implement sparse attention is also provided below:

Once again – I don’t have enough information on how sparse modeling and few-shot learning impact ChatGPT – but the key take-away for me here is that sparse GPT and LLM models are capable of capturing trends and patterns within sequences of data which can be thought of as meta-learning!! This type of meta-learning also occurs within humans and comes naturally to us — most human beings are also able to capture ‘higher order’ knowledge by simply being given a few simple examples of input-output pairs.
Finally, another note by the authors which is captured in the paper is also provided below:
The main advantages of few-shot are a major reduction in the need for task-specific data and reduced potential to learn an overly narrow distribution from a large but narrow fine-tuning dataset. The main disadvantage is that results from this method have so far been much worse than state-of-the-art fine-tuned models.
In other words, although the results are extremely interesting, fine-tuning still seems to be needed in order to make the model perform and generalize the results needed in order to perform well when it comes to human prompts.
Noting this – let’s move on to the next ingredient which I believe also plays a huge role in making ChatGPT as great as it is, which involves training the model to have chain of reasoning capabilities.
Chain of Reason Training
Humans don’t simply produce outputs based on the raw inputs which they receive. Underneath the vast amount of neurons which power us – we use many subconscious processes and algorithms which produce a chain of reasoning which we build up from observing and learning about the world around us.
In the paper Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, the authors show how a chain of thought (a series of intermediate reasoning steps) significantly improve the ability of large language models to perform complex reasoning:

In the above example – you can probably notice that the model doesn’t infer the correct amount of apples from the first prompt. By adding an example where the text demonstrates a ‘chain of reason’ in which the ‘reasoning’ behind the output is given, the model follows a similar path and attempts to produce a ‘chain of reason’ for our apple example. After doing so, it’s able to infer the correct output through this ‘reasoning’ ability. The authors of the paper note that when chain-of-thought prompting is fed into the model, it outperforms standard prompting by quite a large factor in arithmetic, commonsense, and symbolic reasoning benchmarks.
The reasoning behind this is simple: once again, humans don’t simply map inputs to outputs. There’s usually a chain of reasoning which we follow in order to solve complex problems. Let’s go through an example outlined in the paper to show why chain-of-reason prompting may be important in regards to allowing LLMs to ‘infer’ correct answers to these types of problems:
Consider one’s own thought process when solving a complicated reasoning task such as a multi-step math word problem. It is typical to decompose the problem into intermediate steps and solve each before giving the final answer: “After Jane gives 2 flowers to her mom she has 10 . . . then after she gives 3 to her dad she will have 7 . . . so the answer is 7.” The goal of this paper is to endow language models with the ability to generate a similar chain of thought—a coherent series of intermediate reasoning steps that lead to the final answer for a problem. We will show that sufficiently large language models can generate chains of thought if demonstrations of chain-of-thought reasoning are provided in the exemplars for few-shot prompting.
The authors also note that chain-of-thought prompting only works on extremely large LLM models (like GPT-3) and that smaller models tend to produce jumbled chain-of-thought results which don’t necessarily generalize into accurate abstractions which can allow the model to solve real world problems. Once again – we’re shown that extremely large parameter models are capable of capturing ‘meta-learning’ type behavior by being given examples. Through these chain-of-thought examples, they’re able to abstract away concepts which they can use to solve complex tasks.
The paper authors also show the incredible effect which chain-of-thought prompting can have when being applied to a few data-sets which contain challenging math problems (GSM8K, SVAMP, and MAWPS):

The authors note:
Another potential benefit of chain-of-thought prompting could simply be that such prompts allow the model to better access relevant knowledge acquired during pre-training. Therefore, we test an alternative configuration where the chain of thought prompt is only given after the answer, isolating whether the model actually depends on the produced chain of thought to give the final answer. This variant performs about the same as the baseline, which suggests that the sequential reasoning embodied in the chain of thought is useful for reasons beyond just activating knowledge.
We can once again see that these large language models can capture and activate abstractions which allow them to reason about specific tasks through a simple example based approach. They’re capable of capturing patterns within the sequences which are fed in!! Human beings are also capable of generalizing in this manner as well, albeit human beings have a lot more data to work with and are capable of performing more complex tasks!
Mixture of Experts (MoE) Models
ChatGPT 4 most likely isn’t one giant model, but a mixture of various ones which are labeled as ‘experts.’ In other words, instead of creating one huge model which serves all prompts, the model uses a ‘mixture of experts’ or ‘MoE’ which are composed of 8 to 16 different models. There isn’t much info to confirm whether GTP-4 really is a MoE model, but the recently released Mixtral 8x7B model was shown to outperform ChatGPT 3.5 on most standard benchmarks. It consists of 8 separate ‘experts’ which have been optimized through supervised fine-tuning and direct preference optimization (DPO). (Side note: The core insight of direct preference optimization is to derive a loss function that directly solves the policy optimization and reward modeling steps simultaneously rather than having to have a separate ‘reward’ model which evaluates an LLMs response from a set of different possibilities.) To route each prompt to an appropriate model, there’s a router (another neural-network / model) which picks the best two 7 billion parameter models to use and those two models generate the next token to use. The results from these models are then combined and this turns out to be much more efficient than routing each prompt to one giant model, so there are tremendous cost savings in using this approach!
The full diagram showing how this model works is provided below:
You can find a much more thorough write-up of how mixture of experts models work here: Mixture of Experts Explained. No one outside of OpenAI knows for sure the size/architecture of GPT-4, but it's rumored to be a mixture of experts model composed of 16 experts, each of which has over 100 billion parameters. In the case of Mixtral 8x7B, this approach has been shown to be superior to using one large model due to the cost of training 8 smaller ones (which contains only 7 billion parameters) being far lower.
In regards to the actual performance, there are no easy analogies which I can use to understand why the mixture of experts models perform so well. The best one that I can come up with is that ensemble models tend to outperform single or simple models within many machine learning data-sets and real-world scenarios, and this might also be an attempt to use an ensemble albeit this one is composed of many similar LLMs which ‘specialize’ in a more randomized fashion. Of course – OpenAI may have chosen to feed different data-sets into each ‘expert’ model (i.e. such as choosing one expert which specializes in coding tasks, another which may handle a more mathematical domain, and another for creativity, and so on). This was my initial hypothesis, although there isn’t a lot of data which I can use to back this up. Either way, the developments within mixture of experts models are incredibly interesting and there’s a lot of unexplored territory here which I hope to eventually untangle and understand. The best take-away is that these models have a huge advantage in terms of cost since they require a lot less energy to train.
The Mental Model for Understanding LLMs
Andrej Karpathy did a great job of summarizing how LLMs like ChatGPT do what they do in his Intro to Large Language Models. In his talk, he uses a diagram of an OS to show that and LLM can be thought of as a ‘kernel process of an emerging operating system’ which is coordinating a lot of resources and memory to solving various problems:

I’m not an expert, but I tend to view LLMs like ChatGPT as being more like an artificial brain rather than an operating system. Of course, the brain isn’t ‘conscious.’ It doesn’t have any survival instincts which we humans do. It’s simply a huge network which can excel in language tasks by using the properties below:
The context window: you can think of the context window as working memory. Normally, humans have a working memory of only 6-8 items, although unconscious processes which are working underneath our awareness actually make this window much broader. Although the human capacity for keeping things in memory are much more limited that that of ChatGPT, I don’t believe that they are really that far off from representing what a human ‘context window’ is composed of. As an example, although my working memory may not be able to hold much more than a few items that I’m conscious of, when I’m performing a reading task, the words which I encounter from a previous page or previous pages aren’t necessarily ‘unavailable’ to me while I’m reading. As an example – although a novel might introduce a character called ‘Mark’ 10 pages prior to the current one, this doesn’t necessarily mean that I have to expand a lot of effort in retrieving the memories which were associated with the Mark character. My unconscious ‘neural network’ automatically retrieves this information and brings it to my awareness as I’m reading it. You can think of the context window as both the conscious and unconscious ‘cache’ which we humans are equipped with.
Attention is association: you can think of attention as being an auto-associative type of word encoding. It assigns different meanings to words based on the context which they’re presented in. As an example, ‘apple’ may refer to a fruit, or the company (Apple Inc.) – and the word ‘Jobs’ (aka for Steve Jobs) will be associated with the company in a much more entangled manner than with the fruit. This type of associative chaining is accomplished through the self-attention layer. The transformer architecture thus allows for the model to come up with auto-associative relations between a huge amount of textual relations and blocks which it encounters. Humans in a lot of ways function based on associations. A lot of our learning can be encapsulated by the term: 'Neurons that fire together wire together.' In a similar manner – self-attention brings this type of auto-association to transformer networks.
Prediction / backpropagation: The 'unconscious' is composed of many neuronal bundles / cascades which are formed over years of experience. These cascades are automatically triggered and evolved through our past experiences. As an example, when we open a door, we don't have to 'think' about how to open it. This comes from the unconscious mechanism which makes our lives easy: we automatically figure it out based on old patterns. If the unconscious cannot figure it out automatically, the conscious mind is engaged and starts becoming aware of the action. Once aware, the conscious mind's perceptual filer engages in 'retraining' the network. You can think of this process as ‘backpropagation,’ but the brain does it in a different way than a transformer does. The conscious mind is able to view the output and compare it to an expected one and tune the individual module weights by re-trying the action and letting unconscious processes automatically adjust the neuronal weights. A good action is followed by a good emotion (controlled by the amygdala) while a bad one is followed by a bad one – and so we signal to the unconscious that weights must be adjusted. The transformer on the other hand tunes the feed-forward weights in a much more direct manner: it simply looks at the difference between the input and output and can use calculus to figure out which weights within its network to adjust. In this manner, we can think of our feed-forward networks as being neural cascades or ‘predictions’ which get executed based on the text input. Whenever the cascades result in the wrong output, they are adjusted such that the feed-forward network is closer to generating the correct outputs the next time we encounter the same block of text, and so this also very much resembles a process which humans go through.
The cascade which is triggered in a human being depends on many different signals which are sent to the neural module(s). These are never quite 'equal' but are similar for similar inputs. As an example, a great tennis player can hit the ball and has a consistent set of neuronal cascades which are triggered based on the height and speed of the ball which the tennis player encounters. No tennis ball or input is quite the same, but the unconscious is able to 'adjust' based on the feedback it has and its output adapts to make the ball function according to what it views as a 'success.' Initially, the player may not have the optimal output – but over years of training, the player tunes the underlying unconscious network to perform according to a set of expectations. In a similar manner – a transformer or GPT model substitutes huge volumes of text as its ‘years of training.’ By feeding in huge amounts of textual information into our network, it’s able to generate all sorts of associations and cascades which are suitable for generating the appropriate responses to many human prompts / inputs.
The brain itself is a predictive machine. It tries to send actions to be performed unconsciously while trying to predict the next sequence - as well as what it needs to do in order to get through the next sequence of events. A great and funny overview of this can be shown here (where a man goes through an episode of consciously interrupting opening doors on purpose in order to document the experience: “Paying attention to my hands opening and closing doors and drawers 1. increased my awareness of that activity, which 2. interrupted my "looking ahead to the next action in the sequence" mentality, which 3. increased my "being" in the "here and now"--at least for the door knob/drawer knob action.” In other words - being 'here and now' is not the default action of the frontal lobes. The default action is preparing for the next set of steps and 'looking ahead' to prepare for the next set of steps which need to be executed. In a similar manner, transformers and GPT models are auto-associative prediction networks which are constantly looking for feedback in whether their predictions meet expectations and adjusting their ‘internal model’ to match the real world.
We can associate our transformer feed-forward networks as automatically programmed neural ‘cascades’ which are generated from a huge amount of training data, while the backpropagation mechanism can be associated with ‘consciousness’ – although the consciousness in this context simply refers to the model being able to ‘adjust’ and ‘think’ about the discrepancies between its own representations and the ones which are presented to it through real-world feedback.
Capturing patterns: human beings aren’t simple auto-associative cascade networks. Humans are capable of compression information and capturing trends within data. In a similar manner, ChatGPT and large LLMs have been shown to be able to also model these patterns and to capture trends within textual input. As an example, few-shot learning shows that GPT has meta-learning components which can take examples and automatically figure out pattern and word-completion tasks, so the models themselves aren’t simple statistical predictors and function approximators. These networks are capable of capturing relationships and patterns in a much more generalizable manner in the same way that people can. This is accomplished by having a deep neural network in combination with sparse self-attention layers which are able to find associations and deep level structures within text and through having a huge volume of training data. The human brain itself also does this as well, albeit using different training data and different algorithms to do so.
Fine-tuning is intuition and feedback: human beings perform fine-tuning naturally, as we seek feedback from our environment and constantly use emotional triggers in order to aid us in understanding whether our ‘output’ is received in a good way or not. Transformer models don’t have this, so manual fine-tuning is performed and a reward model is trained to distinguish between appropriate language-task responses and inappropriate ones. The reward-model is then furthermore used in choosing a response to generate. This can be thought of as augmenting the base language layer with the intuition as to what types of responses to generate which are appropriate to each context. You can also think of this reward-model as being the ‘amygdala’ (emotional processing layer within the human brain).
The ingenious approach employed in transitioning from GPT2 to GPT3 and ChatGPT involves training and refining models based on human feedback while utilizing user feedback to continuously improve the system. In a sense, this feedback mechanism is similar to what humans already use. Whenever we generate a response, we produce various ‘simulations’ within our own mental landscape to try to asses what our options are. Based on what we think the response will be to our response, we then produce the output which we believe is the most appropriate to the situation at hand. In order to evaluate which output is best, we use a plethora of mental models which we’ve already built up throughout our lifetimes.
The feedback might come in various forms; at a party with guests, the feedback would be in the form of guests responding to your comments; in school, we might receive delayed responses to our test answers in the form of grades. In every setting, we receive feedback to the actions which we choose to enact on the world.
Of course, each individual will perceive the feedback itself differently since our mental models and beliefs differ. ChatGPT receives feedback in a more uniform way since the feedback mechanism is more direct. Although the individual humans giving it feedback may have different views on what constitutes a ‘great’ answer, the ChatGPT system still processes feedback using a similar methodology that humans do: it outputs responses and asks the participants to rate them. Using these ratings, the system itself then knows what constitutes as a ‘good’ response vs a ‘bad’ response and it continues on in evaluating and generating new answers. In trying to capture the data which it needs to pay attention to in order to excel at generating text, it’s deep feed-forward model is able to capture all sorts of information about language and automatically and use this data to build semantically meaningful representations which it’s able to furthermore utilize in continuing to improve its own models of the world.
Chain of thought prompting is logic and reasoning: This teaches the model to develop more of an intuition behind causality and figure out more complex relationships between textual encodings. Humans too go through this process when going through school: we’re given many problems with examples and solutions to work through and/or which we attempt to solve. Though this process, we learn how to model the world more accurately and it allows us to develop a perceived ‘chain of reasoning’ behind each action. In a similar manner – you can think of the chain of thought prompting as allowing our model to infer or try to infer ‘causality’ by providing it with examples. By introducing this causal chain – the model can generalize in a much better manner and can produce more meaningful and correct representations of the world.
The mixture of experts model(s): they are used are mostly there to save computational costs and for efficiency reasons, but you can also think of these as modeling the 2 hemispheres within human brain. Each brain has a left and right side, and each side has to coordinate or ‘vote’ on which action to take (along with having different specializations). You can think of mixture of experts as modeling this hemispheric specialization – at least in the Mixtral models which I’ve explored thus far (i.e. there is a ‘routing’ network which routes to 2 separate areas which vote on what ‘neuronal bundles’ to engage based on the task or phrase on hand). This analogy may not be the best since some models have way more than 2 experts / models, but it’s the best one I can come up with for now.
In sum, ChatGPT is a miracle of engineering and in many ways has revolutionized the field of AI. I continue to be astounded by the capabilities which are being added to the current model and by the amazing landscape of new large-language models being developed.
Noting this, I also wanted to make something clear: although I may have drawn some analogies behind ChatGPT and some ideas behind human thinking, in no way do I believe that GPT nor any LLM models out there represent a conscious being. The human brain is far more complex and has many more components that what I outlined in some of my analogies above. If we were to truly embark to develop a human level AGI agent, we would need 1) far more compute than what’s available 2) more models being able to simulate ‘emotion’ or the amygdala region and 3) evolutionary and evolution based reinforcement learning algorithms which breed survival and competition.
I’m going to end this write-up by providing one of my favorite articles on the human brain. It’s a write up called ‘Overlapping Solutions’ by David Eagleman and it does a great job of highlighting some of the major complexities and intricate details needed in order to really fathom the magic behind human thinking.
Overlapping Solutions
For centuries, neuroscience attempted to neatly assign labels to the various parts of the brain: this is the area for language, this one for morality, this for tool use, color detection, face recognition, and so on. This search for an orderly brain map started off as a viable endeavor, but turned out to be misguided.
The deep and beautiful trick of the brain is more interesting: it possesses multiple, overlapping ways of dealing with the world. It is a machine built of conflicting parts. It is a representative democracy that functions by competition among parties who all believe they know the right way to solve the problem.
As a result, we can get mad at ourselves, argue with ourselves, curse at ourselves and contract with ourselves. We can feel conflicted. These sorts of neural battles lie behind marital infidelity, relapses into addiction, cheating on diets, breaking of New Year’s resolutions – all situations in which some parts of a person want one thing and other parts another.
These are things which modern machines simply do not do. Your car cannot be conflicted about which way to turn: it has one steering wheel commanded by only one driver, and it follows directions without complaint.
Brains, on the other hand, can be of two minds, and often many more. We don’t know whether to turn toward the cake or away from it, because there are several sets of hands on the steering wheel of behavior.
Take memory. Under normal circumstances, memories of daily events are consolidated by an area of the brain called the hippocampus. But in frightening situations – such as a car accident or a robbery – another area, the amygdala, also lays down memories along an independent, secondary memory track. Amygdala memories have a different quality to them: they are difficult to erase and they can return in “flash-bulb” fashion – a common description of rape victims and war veterans. In other words, there is more than one way to lay down memory. We’re not talking about memories of different events, but different memories of the same event. There may be even more than two factions involved, all writing down information and later competing to tell the story. The unity of memory is an illusion.
And consider the different systems involved in decision making: some are fast, automatic and below the surface of conscious awareness; others are slow, cognitive, and conscious. And there’s no reason to assume there are only two systems; there may well be a spectrum. Some networks in the brain are implicated in long-term decisions, others in short-term impulses (and there may be a fleet of medium-term biases as well).
Attention, also, has also recently come to be understood as the end result of multiple, competing networks, some for focused, dedicated attention to a specific task, and others for monitoring broadly (vigilance). They are always locked in competition to steer the actions of the organism.
On a larger anatomical scale, the two hemispheres of the brain, left and right, can be understood as overlapping systems that compete. We know this from patients whose hemispheres are disconnected: they essentially function with two independent brains. For example, put a pencil in each hand, and they can simultaneously draw incompatible figures such as a circle and a triangle. The two hemispheres function differently in the domains of language, abstract thinking, story construction, inference, memory, gambling strategies, and so on. The two halves constitute a team of rivals: agents with the same goals but slightly different ways of going about it.
The neural democracy model may be just the thing to dislodge artificial intelligence. We human programmers still approach a problem by assuming there’s a best way to solve it, or that there’s a way it should be solved. But evolution does not solve a problem and then check it off the list. Instead, it ceaselessly reinvents programs, each with overlapping and competing approaches. The lesson is to abandon the question “what’s the most clever way to solve that problem?” in favor of “are there multiple, overlapping ways to solve that problem?” This will be the starting point in ushering in a fruitful new age of elegantly inelegant computational devices.
Source: https://www.edge.org/response-detail/11663
Finally
This write-up has been a very long journey for me and I hope that you find it useful in helping explain how large-language models like ChatGPT work. I went into very long detail on showing the architectural principles behind transformers (including encoder-decoder models). If you like this write-up, please like and share or if you have any feedback for me, let me know in the comments.

Appendix
Deciphering Encoder Architecture and Matrix Mechanics
Matrix multiplication
Although the definition of matrix multiplication can be a little confusing, an explicit multiplication might clarify this simple task. We’ll multiply the two following matrices to quickly show an example of matrix multiplication for anyone needing a refresher:

Since A is a 2x3 matrix and B is a 3x2 matrix, we know that the result of the multiplication is a 2x2 matrix:
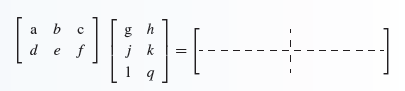
Let’s go through the steps below:
Step 1: We multiply the 1st column of M by the 1st row of N to get our entry at [1, 1]:

Step 2: We multiply the 1st column of M by the 2nd row of N to get our entry at [1, 2]:
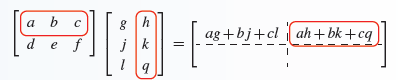
Step 3: We multiply the 2nd column of M by the 1st row of N to get our entry at [2, 1]:

Step 4: We multiply the 2nd column of M by the 2nd row of N to get our entry at [2, 2]:

In a nutshell, matrix multiplication can also be interpreted as a linear transformation on a set of vectors. To perform this linear transformation, we use dot products. The dot product is taken between every row in our first matrix by every column in our 2nd matrix. To put it more formally, if we have matrix A and B and we multiply the 2 matrices to get AB, the elements located at index (i, j) in our product matrix is the dot product between the ith row of A and jth column of B:

Let’s take our word encodings (which contain the semantic and positional information in vector format and transform them into a matrix):
Sentence: I like to read.
Example vector representation (with a dimensionality of 3):
I - > [0.4, 0.0, 0.0]
like - > [-0.2, 0.3, -0.1]
to - > [0.5, -0.1, 0.8]
read - > [-0.2, 0.1, -0.1]
Instead of feeding in each individual vector/word into our self-attention step, we actually feed in a matrix containing each word (inserted as a separate) row and we perform out calculations and the needed steps needed in order perform our attention steps on the matrix itself:
[ 0.4, 0.0, 0.0 ]
[-0.2, 0.3, -0.1 ]
[ 0.5, -0.1, 0.8 ]
[-0.2, 0.1, -0.1 ]
We’ll summarize what happens in a visual manner and then go through each step. The image used in the paper to show how the attention is computed along with helpful annotations is provided below:

1) Computing query / key similarity:

Here, the dot product of each row containing the query word vector in in our query matrix is multiplied by each column in our transposed key matrix (which represents the corresponding key word vector) to obtain the similarity score between each query-key vector pair that we have within our Q and K matrix elements.
Let’s suppose that we have a matrix of 4 words which we are feeding into our input. This would result in 4 separate rows in our query, key, and value matrices. The multiplication step would result in a 4 by 4 matrix containing a similarity score (dot product) with high scores given to words which have a high similarity mapping while low scores (negative value or 0 valued) to words which aren’t mapped similarly.
In our example-illustration above, we would get a 2x2 matrix since we are only feeding int 2 words (each matrix has 2 rows).

2) Scaling:

The dot products in the attention computation can have large magnitudes and can move the arguments of the softmax function into a region where the largest value completely dominates. This makes the model difficult to train. To avoid this behavior, the resulting query / key similarity matrix is scaled by the square root of the query / key / value vector dimension(s).
If our query and key vectors are of length 64 as an example, the matrix values are all divided by 8 (square root of 64) to perform this scaling.
3) Soft-max computation (normalizing each similarity value to a valid probability mapping):
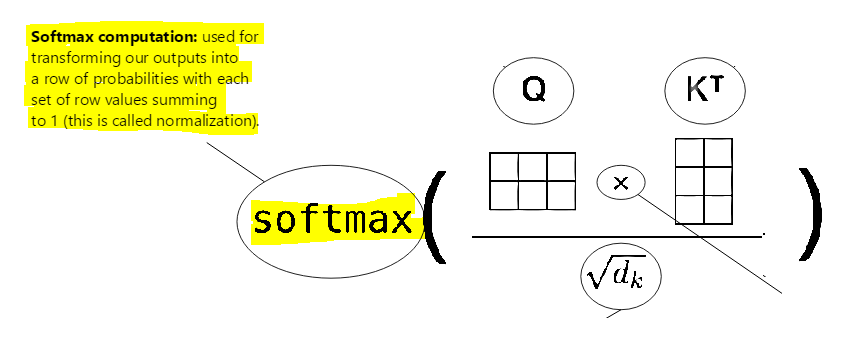
This step takes each resulting key value for each query word / vector and turns the resulting scaled dot product value into a probability. All of the probabilities across the query to key mapping end up summing to 1 (100%) so an example mapping of I love to read scaled dot product matrix provided below:
Attention score for "I" attending to "I": 0.16
Attention score for "I" attending to "like": 0.42
Attention score for "I" attending to "to": 0.2
Attention score for "I" attending to "read": 0.22
To calculate the probability values, we need to normalize these scores using the softmax function. The softmax function transforms the scores into a probability distribution where the values sum up to 1.
First, let's exponentiate the scores:
exp(0.16) ≈ 1.174
exp(0.42) ≈ 1.523
exp(0.2) ≈ 1.221
exp(0.22) ≈ 1.245
Next, we calculate the sum of these exponentiated scores:
1.174 + 1.523 + 1.221 + 1.245 ≈ 5.163
Finally, we divide each exponentiated score by the sum to obtain the normalized probability values:
Probability for "I" attending to "I": 1.174 / 5.163 ≈ 0.23
Probability for "I" attending to "like": 1.523 / 5.163 ≈ 0.29
Probability for "I" attending to "to": 1.221 / 5.163 ≈ 0.24
Probability for "I" attending to "read": 1.245 / 5.163 ≈ 0.24
These are the approximate probability values for each mapping after passing through the softmax calculation, and as you can note that when we sum up all of the resulting values, we get 1:
0.23 + 0.29 + 0.24 + 0.24 = 1
Although the above takes us through an example calculation – the end product after the softmax would result once again in a 4x4 matrix mapping each query vector to the scaled and normalized key:

4) Multiplication by value matrix:

Finally, we multiply our normalized query to key value probability matrix (containing the query to key mapping score) by our value matrix values (containing our value vector on each row) to get a resulting summed product of each query to value mapping.
The primary intuition here is to take the values of the words we want to focus on and to drown-out irrelevant words by using our scaled and normalized dot-product similarity mapping for each input value.
As an example, if we were to use our original example ‘I love to read’ and isolate the matrix multiplications which take place, we would get something like the image below:

Multiplying the 2 matrices above would essentially result in a ‘scaled’ value vector encoding with each one of our value dimensions (2nd matrix column-vector) being multiplied by each normalized attention score (1st matrix row-vector).
Once again, every entry at index (i, j) in our first matrix contains our normalized and scaled dot-product ‘similarity’ computations containing the similarity values between the query word present in our input at position i compared against the key-word present in column j. Our first row vector as an example for the input ‘I love to read’ would contain the ‘similarity’ score mapping between the query word ‘I’ to each key word - > ‘I’, ‘love’, ‘to’, ‘read’.

In the same manner, the column vectors in our 2nd value matrix hold the jth dimensional mapping for each value present for each word present in our input:

Multiplying the 2 matrices above would result in a matrix containing the dot product between the ith row of our attention score matrix (which represents the normalized attention score vector for word i from our input) and the jth column of our value matrix representing the jth embedding dimension for each input word.
In other words, we are ‘scaling’ each value projection by a ‘growth’ and ‘shrink’ factor which we realize by computing our query to key attention score and multiplying each value within it to a mapping within our value matrix.
The end result would be a value matrix scaled by our attention scores!
References and Links
Much of the above work and many of the illustrations are not my own, so a full list of referenced articles / books / papers is provided below:
Attention is All You Need (Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin)
What Are Transformer Models and How Do They Work? (Luis Serrano)
What are Transformer Neural Networks? (Ari Seff)
Illustrated Guide to Transformers- Step by Step Explanation. (Michael Phi)
Attention Is All You Need - Paper Explained. (Matt Namvarpour)
Understanding Deep Learning. (Simon J.D. Prince)
Inside language models (from GPT to Olympus). (Alan D. Thompson)
Illustrated Guide to Transformers Neural Network: A step by step explanation. (Michael Nguyen)
Transformer Feed-Forward Layers Are Key-Value Memories. (Mor Geva, Roei Schuster, Jonathan Berant, Omer Levy)
Neurons in Large Language Models: Dead, N-gram, Positional. (Elena Voita, Javier Ferrando, Christoforos Nalmpantis)
Neurons in LLMs - Dead, N-gram, Positional. (Lena Voita)
Language Models are Few-Shot Learners. (Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei)
Training language models to follow instructions with human feedback. (Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe)
Generating Long Sequences with Sparse Transformers. (Rewon Child, Scott Gray, Alec Radford, Ilya Sutskever)
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. (Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou)
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. (William Fedus, Barret Zoph, Noam Shazeer)
Mixture of Experts Explained. (Sanseviero, et al.)
Intro to Large Language Models. (Andrej Karpathy)
Fluxus Research: Opening and Closing Doors and Drawers. (Allen Bukoff)
Ceaseless Reinvention Leads To Overlapping Solutions. (David M. Eagleman)