
Photon-Lines Tech Notes - July 2025
My own favorite notes & highlights from the world of tech - July 2025 Edition

I told myself that I’d make an attempt to post explanations for interesting things on a monthly basis – but let’s face it, accomplishing that given my current work-load is going to be difficult, so in instances where I can’t meet this deadline, I’m simply going to post my own notes on interesting topics that I’ve read on Hacker news and other various tech outlets.
Noting this, here are some of my favorite articles from Hacker news which I’ve made notes on over the last month.
Reflections on OpenAI
Kevin French-Owen (a former OpenAI employee) makes some notes on what his experience was while working for OpenAI which can be found here, and some special items of note which every company can learn from are provided below:
The company has grown rapidly from 2024 (from 1,000 to 3,000 employees).
Organization started off more like Los Alamos (many different projects and directions along with researchers probing the cutting edge of science) and one group happened to have accidental spawned the most viral consumer app in history (ChatGPT).
Everything there runs on Slack (there is no email) so the communication is very open within the org.
There is no road-map and everything is bottom-up rather than top-down: good ideas come out of anywhere.
Rather than having a master plan, progress is iterative and uncovered as new research is done.
Very meritocratic culture (best ideas tend to win) and a strong bias for action (you don’t need to ask for permission – you just get things done).
Strong bias to just ‘work on your own thing’ and see if it pans out and each researcher is treated as a ‘mini-executive’ (i.e. they decide what they work on).
The company changes direction quickly and this is valued a lot.
They value doing the right thing rather than trying to stay ‘on course’ and use new information to steer the project in the right direction – if new information shows that the strategy or plan needs to change, then it’s changed.
They pay attention what is happening at other companies who are also attempting to tackle AGI (like Google, Meta, Anthropic) and they are pretty sure the other companies are also paying attention to them.
They have extraordinarily high GPU costs and everything else pales in comparison (not a really huge surprise).
They are incredibly ambitious in what they want to accomplish. You’d think that coming up with ChatGPT would deter them a bit, but they have plans to dominate / succeed in other areas as well.
Teams are extremely fluid. If something needs to get done, team member from other teams can easily be on-boarded and brought into the new team (as an example, 2 members of the ChatGPT team joined the Codex team when they needed to hit a launch date).
Leadership is quite visibly and heavily involved (i.e. every exec was dialed in and communicating with the rest of the team on Slack).
The team uses a giant monorepo to host the code, and most of the code is written in Python. Everything is run on Azure.
They have a lot of members which they brought over from Meta / Instagram and their early infra also resembles Meta.
‘Most ideas start out as small-scale experiments. If the results look promising, they then get incorporated into a bigger run.’
Author notes and writes about sleepless nights where he had to work frantically prior to codex launch to make the project happen and on schedule (i.e. they move fast and work hard to make things happen).
The original article goes into much more detail than I did above, but I figured that I’d share some of the key highlights that I made note of. Overall, OpenAI is more like a very driven and very ambitious research lab running decentralized teams that are given freedom to take rapid action and work on interesting and ambitious projects. They also prefer to take actions and ship things quickly, and they made some really smart decisions on the infrastructure side as well which I think greatly helped them out.
How does diffusion / CLIP (AI driven image / video generation) work?
3Blue1Brown (my favorite math Youtuber) and Welch Labs collaborated together to produce a masterpiece which describes the gist of how diffusion and video generation models (like CLIP) work and you can find their excellent explanation here.
For anyone who wants a very high-level summary, it’s provided below:
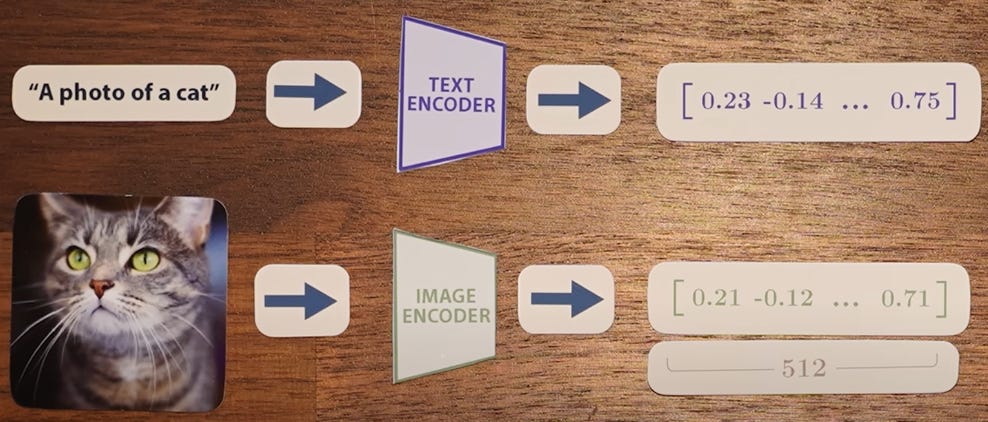
In February 2021, a team at OpenAI released a new model architecture called clip. It trained on a data-set of 400 million image + caption pairs scraped directly from the internet.
Clip is composed of 2 models – one that processes text and the other that processes images. The output of each of these 2 models is a vector of length 512.
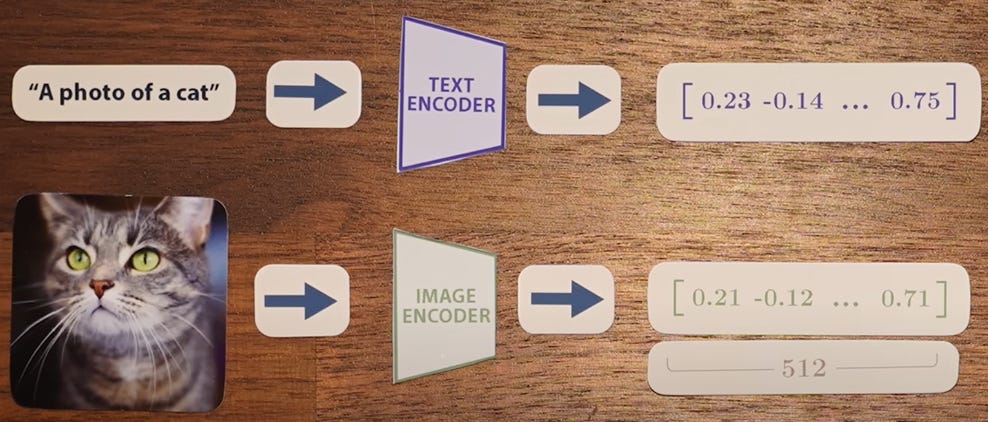
In essence, the encoded text and image are supposed to be ‘similar.’ That way, the images could be associated with the textual encoding / representation.
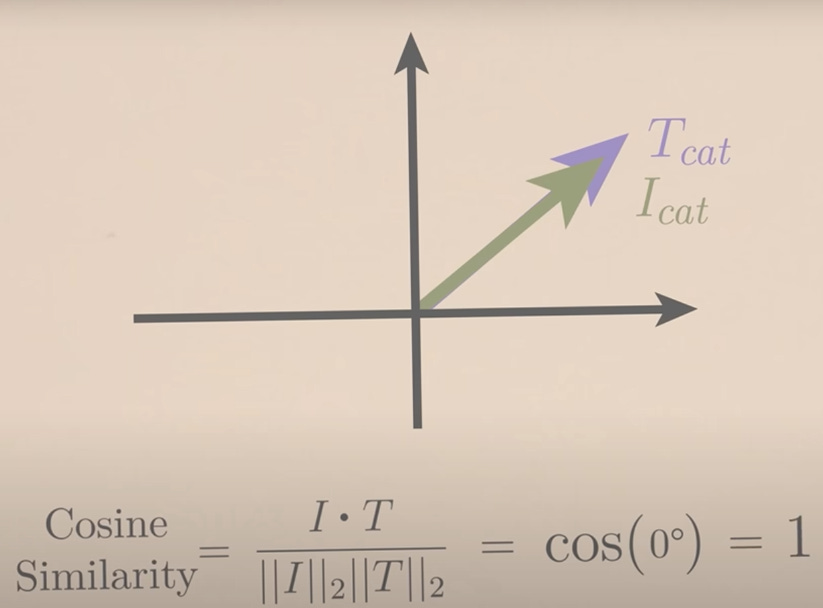
To ensure that the 512 dimensional vectors are similar, OpenAI used a clever approach: it used a cosine similarity metric (i.e. it took the cosine of each text / image vector and attempted to maximize it).
To get an intuition of how cosine similarity works, you can use the image below:
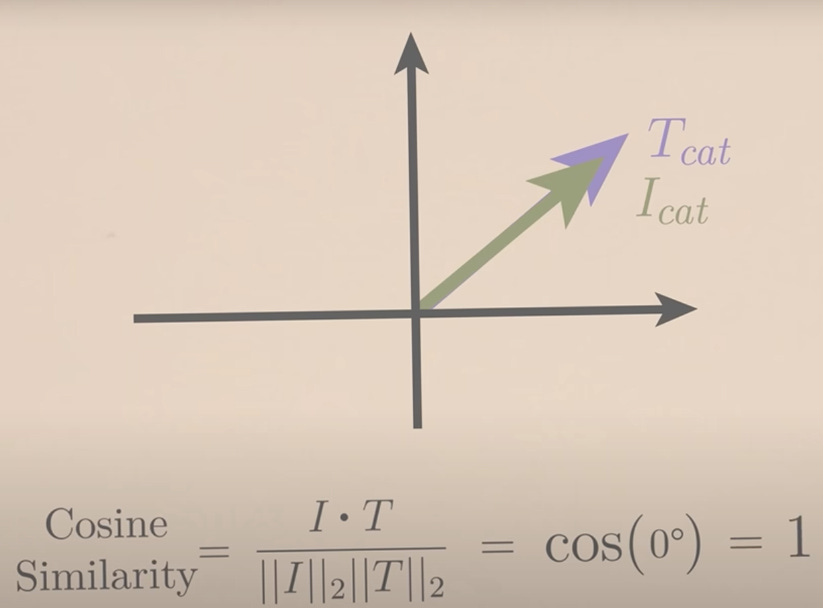
You should be able to notice that in the above vector space, the image for cat points in the same direction of the textual representation: and thus the cosine between their vectors is 1 and thus maximizing the cosine similarity between each image and text was done while the opposite was true for non-matching and contrasting image / text pairs: in those instances, the model tried to minimize the cosine similarity (thus attempting to represent dissimilar data as being ‘distant’ from the original vectors in that space).
In the below image, you can see 3 image / text pairs and the diagonals within the matrix which contain the matching image and text info align (i.e. have a high cosine similarity) while the non-diagonal entries (non-matching image & text) have a more distant similarity score:

The learned geometry of this shared vector space has some really interesting properties. Let’s say that someone takes one image of themselves not wearing a hat, and then right after putting a hat on, takes another image of them wearing a hat – and pass both of these into our image model. In the result set, we get 2 separate 512 dimensional vectors in our embedding space. Now...if you take the vector of that someone wearing a hat and subtract it from the image of them not wearing a hat, we get a new vector in that embedding space.
Now – you think to yourself – what text might this vector correspond to? Yes – the vector we get from performing the above operation is the encoding of a ‘hat’ (with the 2nd most similar word being ‘cap’)!!!

In essence, CLIP gives us an excellent way of encoding a shared representation of image and text. However, CLIP only gives us a way of embedding our original image / text data into a shared embedding space in one direction. We have no way of generating actual image / text from our resulting embedding space / vectors.
A few weeks after GPT3 came out, a team at Berkeley came out with a paper called Denoising Diffusion Probabilistic Models (known as DDPM). The core idea behind these models is pretty straight forward:
You take a set of training images and you add noise to the images in a step-by-step manner until the image is completely destroyed:

From here, we create a neural network to reverse this process (and regenerate the original image) and the neural network is asked to do this in one step:

The surprise? The neural network which is trained and which produces the output doesn’t just attempt to create the final output vector – random noise / steps are added to the final image as well (which produces much better results).
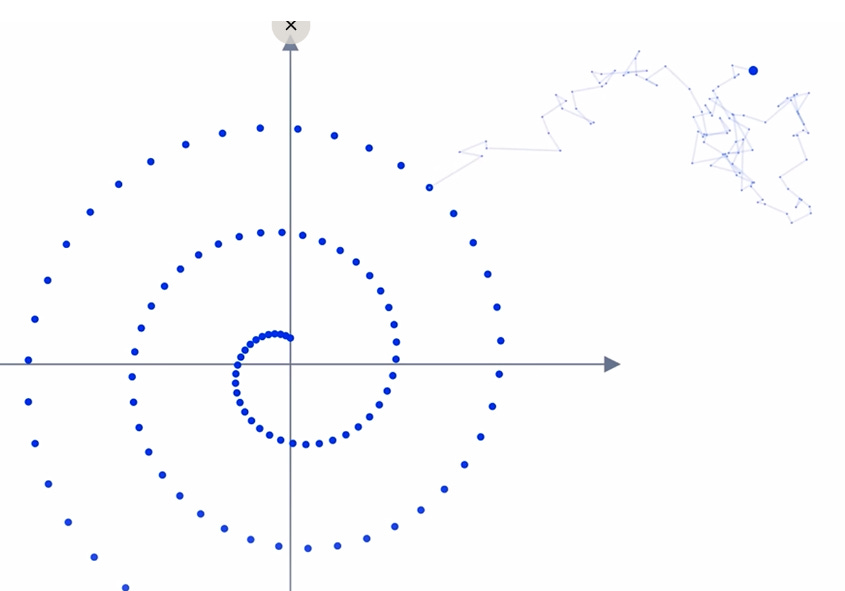
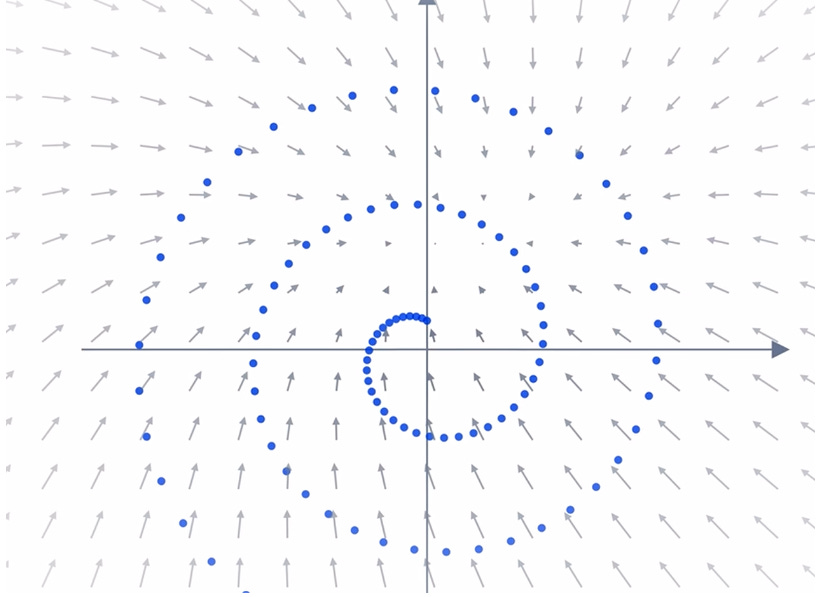
You can think of the first step of adding noise to a diffusion model as being similar to Brownian motion (i.e. a random walk) across our image space. Each image point is distributed across the image randomly in a step by step manner (and in a random direction). In the below example, we show a spiral image and a sample of where 1 point may go through after taking 100 random steps:
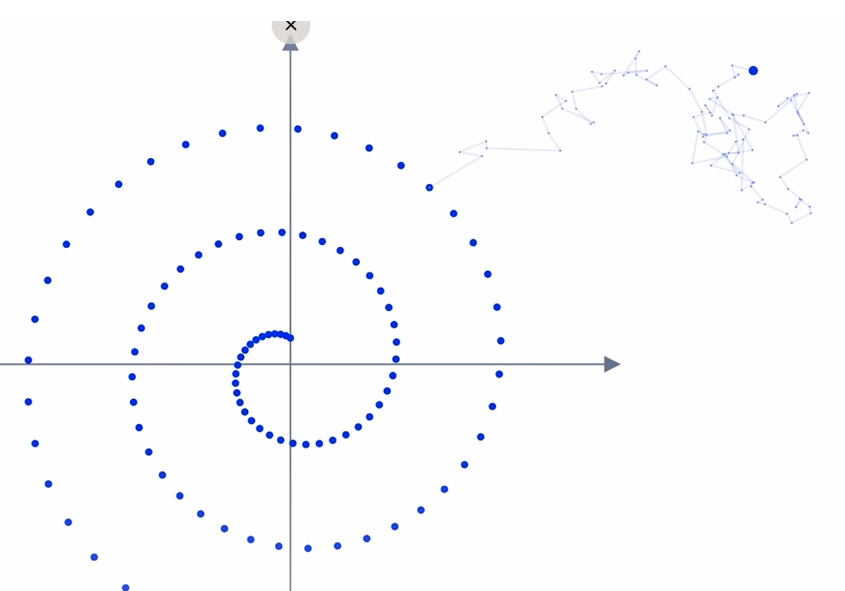
Our model in essence will see many random walks starting from our original image – and we’re essentially asking it to reverse the clock. How can our model learn to do this though? Our ‘walks’ are random after all?
The essence is that our model is NOT trying to actually predict the actual diffusion paths (i.e. Brownian motions) which took place within our model (i.e. steps 100, 99, 98, .... 3, 2, 1, 0) – the model instead tries to predict the total noise added across the entire image (i.e. the neural network must predict the step from 100 -> 0 in one shot):
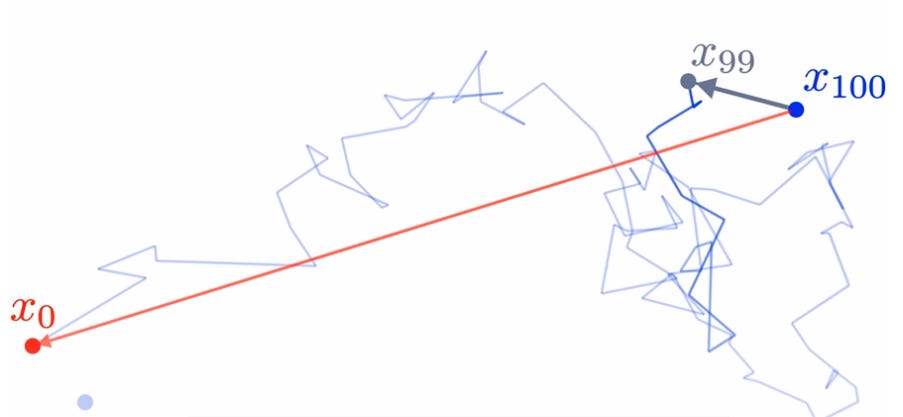
In essence, what this means is that for each point in our resulting space (after we’ve added our noise / diffusion), our neural network learns the vector or set of vectors pointing back to the original data distribution and this is extremely valuable information to have – we can grok the general resulting vector field produced by the neural network by looking at the image below (where the neural-network learns to reconstruct the spiral after adding random noise to each point in the spiral image).
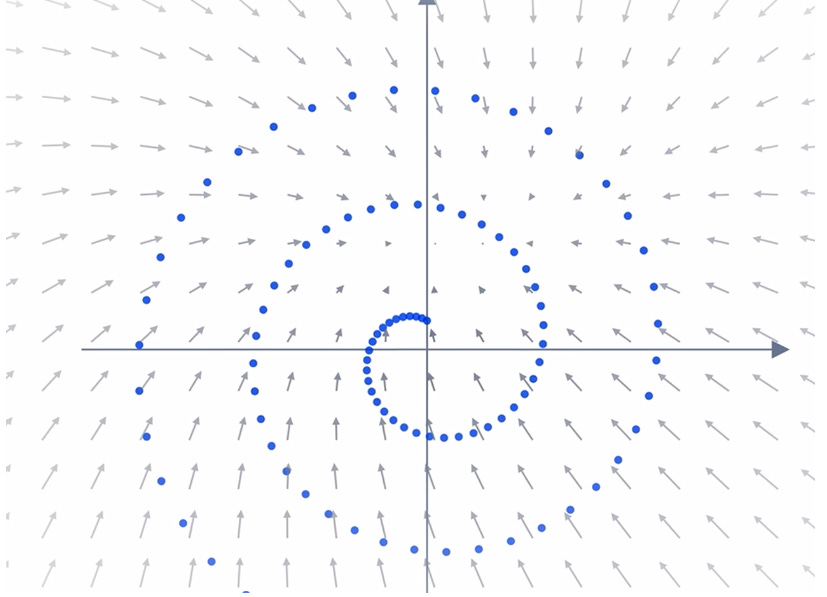
An interesting phenomenon occurs after a large number of random steps are added to the model: a ‘phase transition’ occurs where the vector field which points back to our original image stops pointing towards the center of the original image and starts pointing to the actual / original image itself. In other words – adding noise plays a huge role in making sure that our model works.
In a similar manner, when attempting to reconstruct the original image – adding noise plays a vital role in the reverse direction as well!! Let’s go through an example:
Let’s say that we attempt to model a spiral after 100 steps (using our diffusion model).
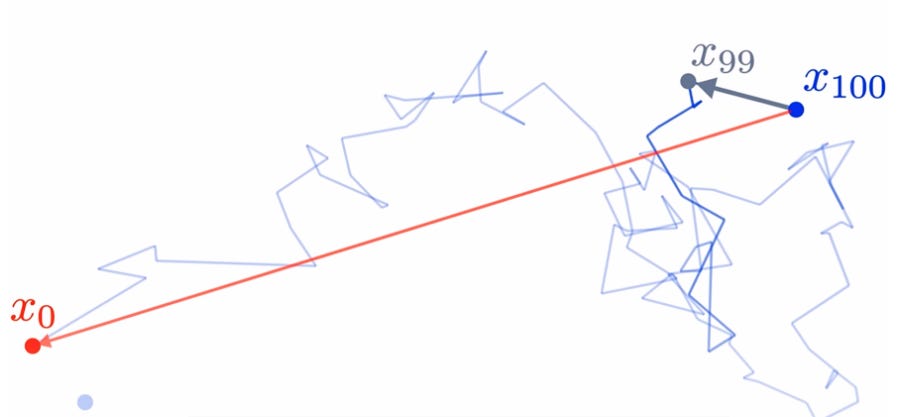
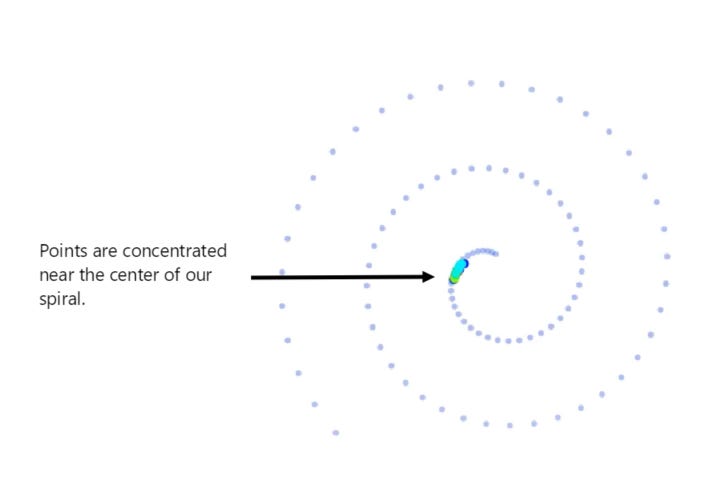
If we don’t add noise as we try to predict where our point will land – we end up with each resulting point taking a walk back to around the center of our original image. As a result – in the below image we show what the neural network reconstructs:
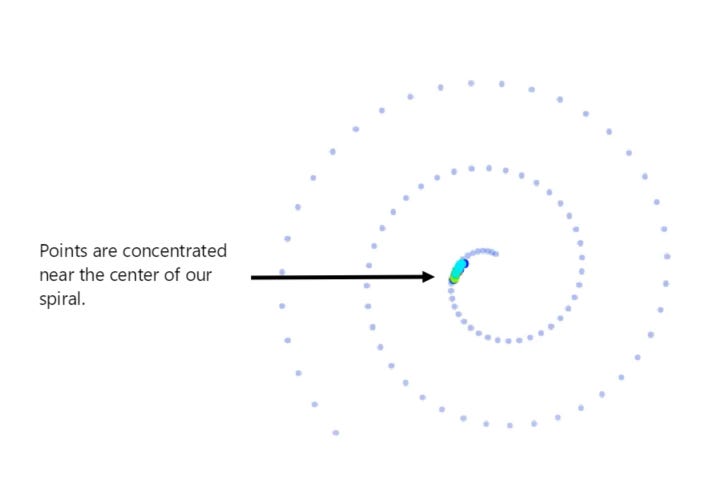
You should be able to notice that the end result doesn’t really resemble our original image but instead re-constructs a small cluster of points near the center of our image.
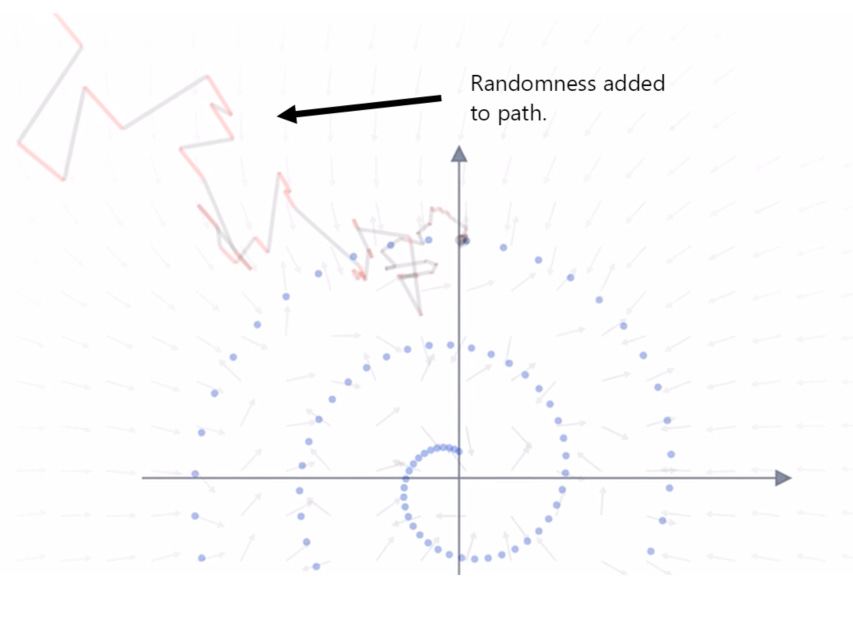
To enable the model to re-construct the essence of the original image – this is why random noise is added as the model attempts to walk each of the resulting Brownian points back: the randomness ensures that each point is walked back to a more broad representation located within our phase space.
In the example below, one sample point is shown and the walk back is given random directions / transitions which results in the point being located away from our center points within our original image:
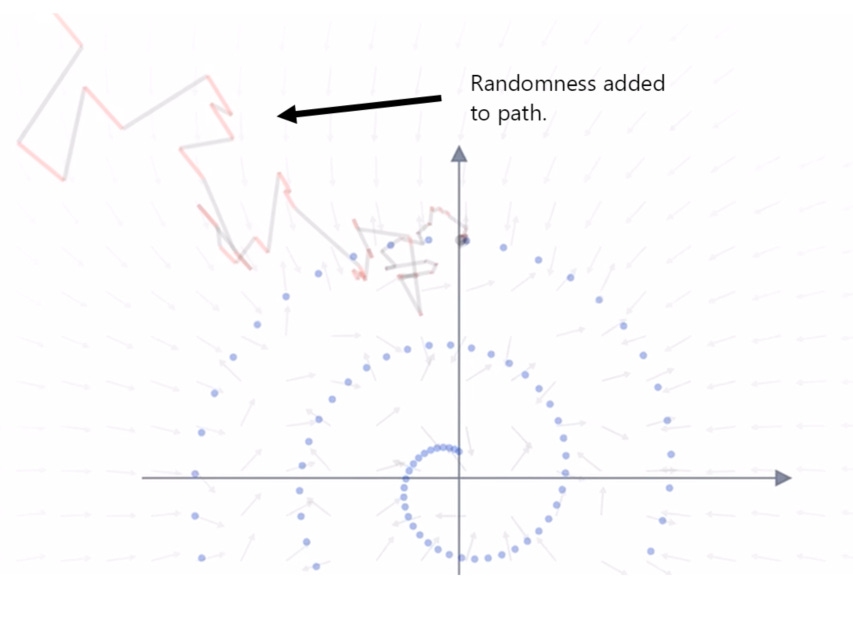
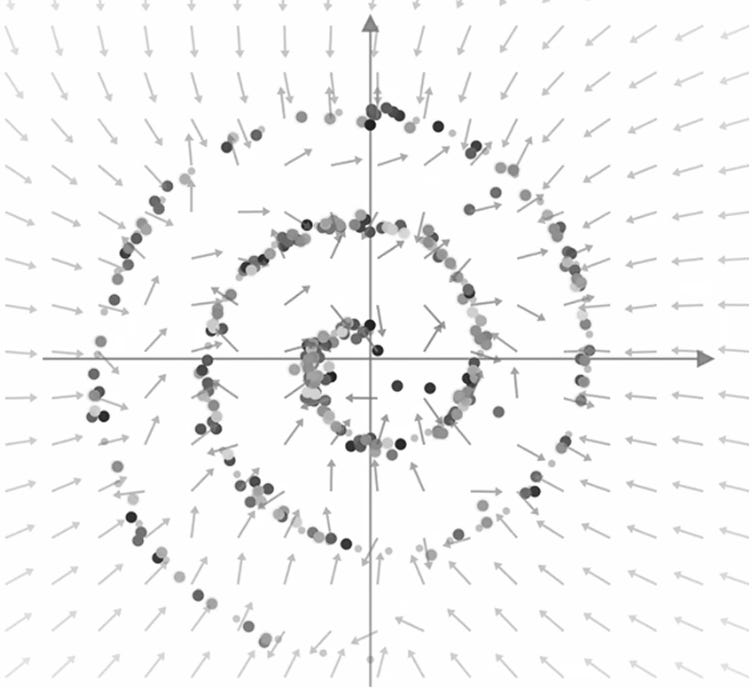
Adding this noise is vitally important: once again, it ensures that the model walks back each point and distributes it along our spiral (instead of focusing each one within the center of the image (or towards the ‘mean’ of our image)). Although the result may look chaotic, the final mapping shows a much more representative ‘image’ of our original sample:
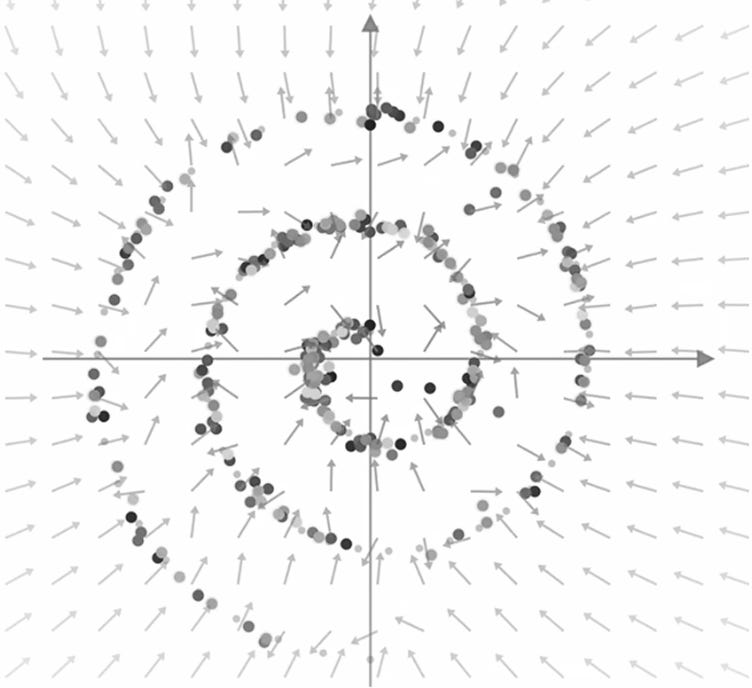
Although the above procedure produced fantastic results – the amount of compute needed to generate the models was large and a Google team found a way to simplify the above process (without the need to add random noise).
To simplify the model, the team turned the original model (modelled by something called a stochastic differential equation which models noise / randomness) into an ordinary differential equation which was equivalent. ODEs ordinary differential equations are much simpler to solve. The change in model allowed their team to lower the amount of compute needed to train the model thus lowering the amount of steps the model needed to take to generate each original image.
In 2022 – another breakthrough at OpenAI occurred. Using textual data – it was able to produce models which generated outstanding images (which represented the embedded textual information):
The model first encoded the textual information into a text encoder which transformed the info into a high-dimensional embedding vector.
A diffusion model took that embedding vector and was used to generate an image (or a video) of what the prompt / text describes.

The resulting model is known today as DOLL-E 2 – but there’s one more step they took in order to make the idea work so the process isn’t quite as simple as what we outlined above. In order to generate the image / video, the model they produced uses something called classifier free guidance.





We won’t go into the full details here, but you should watch the entire video if you want a more in-depth overview as the video in general is outstanding and does a much better job in explaining the nuances of how these models work.
Overall, outstanding video once again by Grand Sanderson (3Blue1Brown) and Welch Labs – full credit goes to them for all of the content above (as well as the images).
Hidden Controls: Lamenting Against Today’s Bad UI Usability
The world today is full of bad software. I’m not going to go into the details on the exact reason why I hate modern interfaces, but the below article identifies one of the key reasons I hate most of them: the HIDDEN CONTROLS!!
Stop Hiding My Controls: Hidden Interface Controls Are Affecting Usability
Making controls visible was something that was highly touted by Douglas Engelbart (an early pioneer and legend within the world of UI design). Human memory is fallible so making things recognizable rather than asking your users to recall information should be part of every great UI design; or at least that’s the gist that needs to be taught and re-taught to modern designers and developers.
In the modern era, computing tasks require a significant amount of knowledge that’s not simply recalled. This is the reason why most users don’t love command lines: you need to use memory (i..e. recall) more than recognition, and it’s one of the reasons why many people prefer the modern desktop experience. Rather than typing things into a terminal, you don’t need to think as hard when using a desktop UI: it makes finding information a breeze by easing the memory burden on you (i.e. by using folders and other metaphors to aid your recall). In the early days, UI specialists knew this and recognized that providing aids to people’s recall / memories helped non-specialist users use it more easily (and thus made computing accessible to almost everyone).
Let’s fast forward 40 years. Using a phone flash-light isn’t very intuitive. You have to swipe-down (since this action isn’t broadly visible to most users – nor is its location really intuitive) — discovering this feature is a royal pain in the a**. Another example is Apple Maps in CarPlay requires you to tap on a button located on the bottom left of the screen (which brings up a search option) and this 1) isn’t very usable nor 2) intuitive at all.
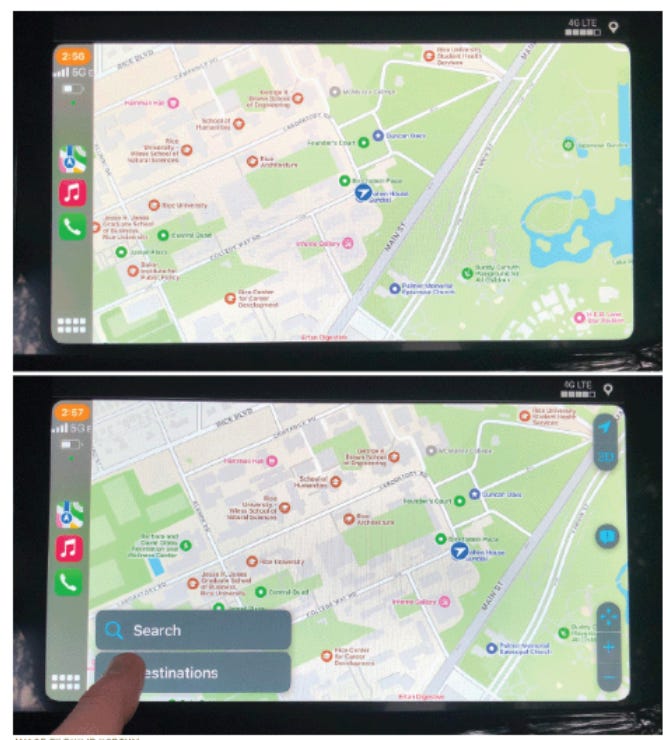
This lack of usability is present everywhere today and most software systems are getting worse.
A major source of hidden controls being everywhere is the number of features that are being shipped with modern software: the need for more functionality within modern systems seems to require us to free up screen space to accommodate all of the visible controls, but designers shouldn’t use this as an excuse: you can still create great software that keeps the key functionality visible and the myriad of options more easy to discover.
As an example, the General Motors’ engineers designed an excellent map interface that balances complexity with visibility and it fixes most of the problems that are present within Apple maps interface:
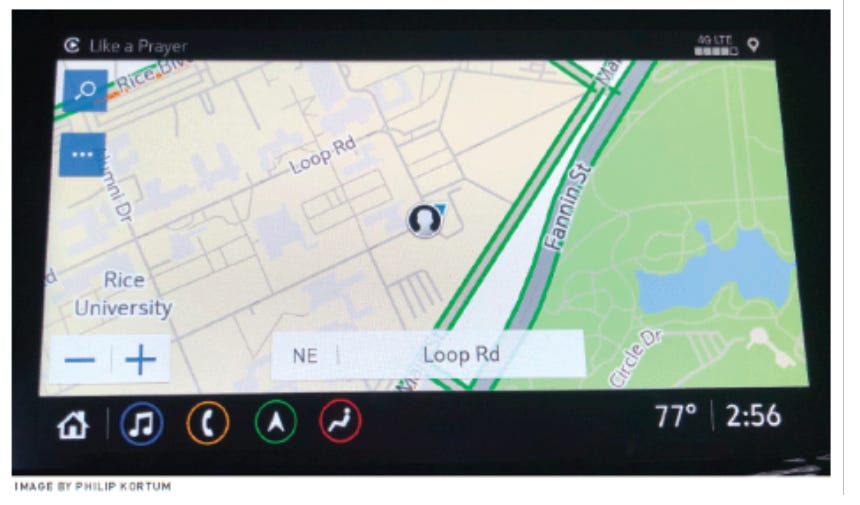
Most great software (and mission critical systems) don’t have hidden controls!! They rely on controls that are
Visible
Persistent
Show the system state
The key actions and functionality within any great software should abide by the 3 properties outlined above! Modern designers need to reevaluate their use of hidden controls and prioritize making modern software more usable.
Why Facts Don’t Change Minds
This is just a fantastic article which goes through a fascinating model which can be used to model beliefs:
https://vasily.cc/blog/facts-dont-change-minds/
The gist of the article is that we can visualize a belief system as a graph i.e. a “network of concepts, values, and connections” and thus, whenever you challenge something – you’re not just challenging that single ‘point’ within the network – you’re also challenging the rest of the nodes and edges which effect the entire graph.
Challenging one point is more like challenging the foundation of a building or cathedral in other words rather than just one brick or stub which supports the building. Of course – most human beings don’t challenge the models which we believe in. Instead – we look for evidence to reinforce them and we actively ignore or dismiss the information which goes against our beliefs. This is why challenging people’s beliefs is so hard. When belief systems are challenged, the real contest isn’t just about exchanging arguments—it’s about trying to reshape the other person’s underlying foundation and structures; it’s about changing the active landscape within their mental world.
The Author uses a graph to illustrate the model of ‘growth-first capitalism’ which is provided below:
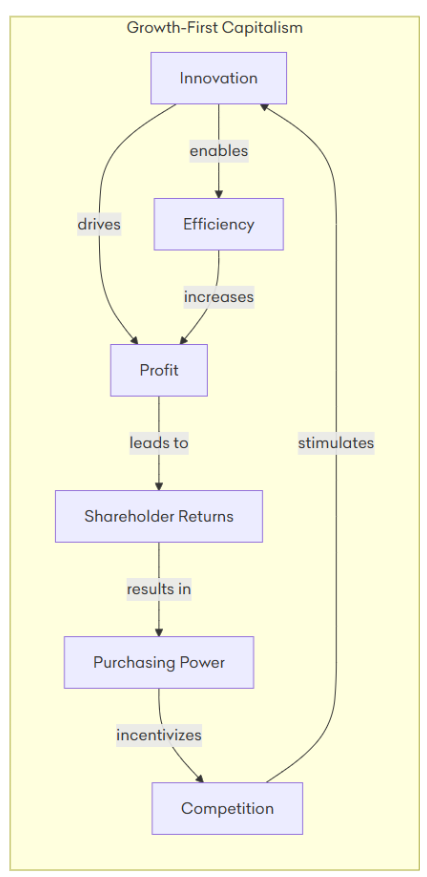
In the growth-first capitalism model, we assume that all of the connections are strong and that profits lead to more shareholder returns, which furthermore drives more investment in innovation – but this re-investment in innovation and growth isn’t necessarily true. In a lot of cases, the maximization of shareholder returns may not necessarily lead to more purchasing power for the company. The company shareholders may instead choose to instead keep the profits for themselves and to attempt to ‘milk’ them for their own personal gain as much as possible (thus breaking the self-reinforcing graph we originally outlined):
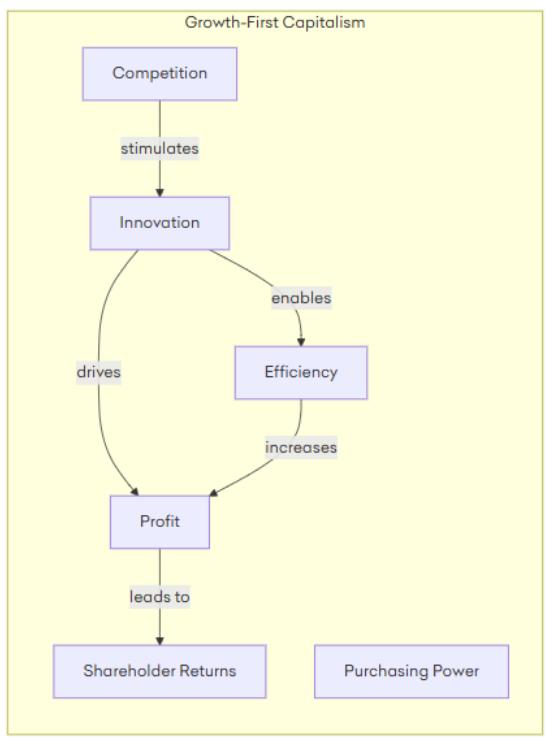
“Attacking the connections between ideas can force a belief system to reroute its logic, making it less direct, more convoluted, and sometimes less persuasive—even if the system doesn’t collapse outright.”
The above example shows how attacking one node can completely change the model and perception of a system: invalidating one of the key assumptions can make us question whether maximizing shareholder value and going all in on ‘growth first capitalism’ is the best thing to do given the fact that it tends to distribute wealth to a select few rather than re-investing it to benefit the many.
“So when you encounter someone whose worldview seems impenetrable, remember: you’re not just arguing with a person, you’re engaging with a living, self-stabilizing information pattern—one that is enacted and protected by the very architecture of human cognition.”
The whole article and write-up is just fantastic and I highly recommend you give it a read.
The Rise and Downfall of Yahoo
This excellent article does a great job of over-viewing what went wrong (and what also went right) within the rise and downfall of Yahoo:
Started off as a website called “Jerry’s Guide to the World Wide Web” by 2 Stanford students in 1994.
Initially, it was more of a directory or portal rather than a search engine: it had categories with linked sub-categories which users could click on to find relevant web-sites.
To become a ‘portal’ to the internet, they recognized that they needed not just to link to content – they also needed to produce it as well. To do this, they acquired other companies and started producing their own stuff. In 1996, they turned their first profit.
Between September 1997 and July 2015, Yahoo made 114 acquisitions.
Some of its acquisitions were disastrous (i.e. acquired Broadcast.com and Geocities.com for 10 billion) while some turned out to be fantastic (i.e. acquired 40% of Chinese e-commerce site Alibaba in 2005 for $1 billion which turned into a 36 billion dollar profit).
Still – their biggest blunder might have been not making 2 major acquisitions which could have radically changed the trajectory of the company:
Yahoo had multiple opportunities to buy Google and failed to do so. In 1998, Yahoo actually turned down the opportunity to acquire Google for $1 million (currently Google has over 1 trillion in market capitalization).
Also whiffed at the opportunity to acquire Facebook in 2006 for 1.1 billion dollars (Facebook today is also a company with over 1 trillion in market cap).
In the end, Yahoo ended up being sold to Verizon in 2016 for about 5 billion dollars (which didn’t end up working out so well for Verizon).
Layoffs at Microsoft
Microsoft announced cuts to 9,000 workers in second wave of major layoffs last month – all while watching their stock / market cap almost double in valuation just over the last 3 months. Their profit margins are also huge. Meanwhile, they’re spending a lot in bringing in cheaper labor from over-seas. Layoffs in the good old days used to be a measure of last resort: you did it when you had to and when your company was very much unprofitable. To lay people off while you are making billions in profit is shameful. It’s an inexcusable thing to do – especially when you’re invested in a technology (an LLM called ChatGPT) that will one day replace a lot of jobs.
I remember when working for a tech-leader used to mean something. So much for that notion.
Noting that, I hope you enjoyed this monthly update.