


A Visual Introduction to Neural Networks
A visual example-focused introduction to neural networks.

Here, we’re going to explore neural networks. Neural networks are a type of machine learning model inspired by the structure and function of the human brain. They are designed to recognize patterns and learn from data in a way that enables them to make predictions. They do this using a method called backpropagation. Before diving into the full details, let’s take a bit of a look at the history of neural nets and where they were first used.
The Perceptron
Invented in 1957 by Frank Rosenblatt, a perceptron is the simplest neural network possible. It’s supposed to represent the computational model of a single neuron. A perceptron consists of one or more inputs, a processor, and a single output.

The inputs are sent into the neuron, processed, and result in an output. We say that this follows a “feed forward” model.
Let’s go through an example of how a 2 input perceptron could process its inputs to produce a desired output by going through one example. Our toy model here is going to be similar to the perceptron we diagrammed earlier, although we will add a weight for each input neuron since these weights are the key to modeling our perceptron state:

To make things even simpler, we’ll rename our input state from ‘input 1’ and ‘input 2’ to x1 and x2 an our weights for each input from ‘weight 1’ and ‘weight 2’ to w1 and w2 – going forward, we’ll also use the variable y to model our resultant output:

So – how does our perceptron produce an output?
Simple. For this perceptron, we’ll just take the inputs (x1 and x2) and multiply them by their respective weights w1 and w2. The weighted inputs are then summed up along with a bias term (denoted as ‘b’ in the formula below) to produce the total input to the perceptron, denoted as z:
z = (w1 * x1) + (w2 * x2) + b
Note: The bias term is a trainable parameter that allows the perceptron to adjust the output even when all the input values are zero. You can think of it as how much we need to ‘pivot’ or move our resulting function up or down in order to get it to produce the correct output.
Next, the total input (z) is passed through an activation function to generate the output (y):
y = activation_function(z)
The output y can be thought of as the final result if the perceptron is used in isolation. Either that, or it can be passed to another layer of perceptrons in a multi-layer neural network, and this is usually how perceptrons are used today.
Overall – the end state diagram is provided below:

Simple Example of a Working Perceptron
Let’s go through a simple example to show how it might process a real set of inputs.
Let's assume we have a perceptron with the following weights and bias:
w1 = 0.6
w2 = 0.4
b = -0.3
And suppose we have the following input data:
x1 = 0.8
x2 = 0.2
In the case of a simple binary output, the activation function is what tells the perceptron whether to “fire” or not. Activation functions can be quite complex, but we won’t add any more complexity here than we need to. To provide an output (or whether our neuron will ‘fire’), we will simply use a step function as the activation function.
A step function produces an output of 1 if the input is greater than or equal to zero and an output of 0 otherwise, so it’s a very simple activation function:

Now, let's calculate the output (y) of the perceptron:
z = (0.6 * 0.8) + (0.4 * 0.2) + (-0.3) = 0.66
y = activation_function(z) = step_function(0.66) = 1 (since 0.66 >= 0)
So, for the given inputs (x1 = 0.8 and x2 = 0.2), the perceptron produces an output (y) of one. This is a simple example of how a perceptron works with two inputs and one output. In practice, perceptrons are combined to form more complex neural networks capable of solving a wide range of tasks.
Training the Perceptron
In our above example, we used random weights and a random value for our bias in order to initialize our perceptron – but is using a randomly initialized function … well … useful? Given a set of data points in a binary classification task (i.e. where each point is classified as being in either one of two available categories) – can we use the above perceptron to make valid classifications based on our input?
Well, I wouldn’t be here writing this introduction / post if this wasn’t possible, so here it goes: yes, indeed we can! And how do we do this?
To train a neural network to answer correctly, we’re going to employ the method of supervised learning. With this method, the perceptron is provided with inputs for which there is a known answer. This way, the perceptron can find out if it has made a correct guess. If it’s incorrect, the network can learn from its mistake and adjust its weights. But how do we know how to adjust the weights (i.e. in what direction) as well as our bias to provide the correct outputs?
Let’s walk through an example and show the exact steps below:
Supervised Learning Approach for Training the Perceptron
Step 1: Data Preparation
We need a dataset with labeled examples. Let's generate some random binary data for this example:
Input Data (x1, x2) | Target Output (Class)
----------------------------------------------
Input Data: (0.2, 0.3) | Target Output: 0
Input Data: (0.8, 0.6) | Target Output: 1
Input Data: (0.5, 0.9) | Target Output: 1
Input Data: (0.4, 0.1) | Target Output: 0
Step 2: Initialize Weights and Bias
As in our previous example, we'll use the same initial weights and bias:
w1 = 0.6
w2 = 0.4
b = -0.3
Step 3: Define the Activation Function and Learning Rate
For this example, we'll use the step function as the activation function, and we'll set the learning rate to 0.1. The learning rate determines how much the weights and bias are updated during training. The step function once again simply outputs 1 if our input is positive and 0 otherwise.
Step 4: Training Loop
We'll iterate through the data-set multiple times (epochs) to train the perceptron. In each epoch, we'll calculate the output of the perceptron for each input and compare it with the target output. We'll then adjust the weights and bias based on the error.
The perceptron’s error can be defined as the difference between the desired answer and its guess.
ERROR = DESIRED OUTPUT - GUESS OUTPUT
In the case of the perceptron, the output has only two possible values: 1 or 0. This means there are only three possible errors.
If the perceptron guesses the correct answer, then the guess equals the desired output and the error is 0. If the correct answer is 0 and we’ve guessed 1, then the error is 0-1 = -1. If the correct answer is 1 and we’ve guessed 0, then the error is 1.
Let’s go through a few epochs and try to visualize what our perceptron is doing in each training step below:
Training steps:
Calculate the total input (z) for each input (x1, x2).
Pass the total input through the step function to get the predicted output (predicted_y).
Compute the error (target_output - predicted_y).
Update the weights and bias using the following update rules:
NEW WEIGHT 1 = OLD WEIGHT 1 + LEARNING_RATE * ERROR * INPUT 1
NEW WEIGHT 2 = OLD WEIGHT 2 + LEARNING_RATE * ERROR * INPUT 2 BIAS = BIAS + LEARNING_RATE * ERROR
Or, if we want to model this in terms of our example it’s simply:
w1 = w1 + learning_rate * error * x1
w2 = w2 + learning_rate * error * x2
b = b + learning_rate * error
Repeat steps 1 to 4 for each example in the dataset.
Note: In practice, it's common to use more sophisticated activation functions (like the sigmoid or ReLU) and optimization techniques (like stochastic gradient descent) for training neural networks. However, for this example, we'll keep it simple with the step function and basic weight updates.
Now, we would go ahead and apply the training steps to the provided data-set for a few epochs. After training, the perceptron should be able to classify new data points into one of the two classes based on the learned weights and bias.
Let's go through a couple of iterations of the training loop using the example we provided above:
Iteration 1:
For the first example (0.2, 0.3) for which the target output is 0:
Calculate total input (z)
= (w1 * x1) + (w2 * x2) + b
= (0.6 * 0.2) + (0.4 * 0.3) + (-0.3)
= 0.09
Predicted output = step_function (0.09) = 1 (since 0.09 >= 0)
Error = target output – predicted output = 0 - 1 = -1 (since the target class is 0 and predicted class is 1).
Update weights and bias:
w1 = 0.6 + (0.1 * -1 * 0.2) = 0.58
w2 = 0.4 + (0.1 * -1 * 0.3) = 0.37
b = -0.3 + (0.1 * -1) = -0.4
Iteration 2:
For the second example (0.8, 0.6) for which the target output is 1:
Calculate total input (z)
= (w1 * x1) + (w2 * x2) + b
= (0.58 * 0.8) + (0.37 * 0.6) + (-0.4)
= 0.4
Predicted output = step_function(0.4) = 1 (since 0.4 >= 0)
Error = target output – predicted output = 1 - 1 = 0 (since the target class is 1 and predicted class is 1).
Update weights and bias:
w1 = 0.58 + (0.1 * 0 * 0.8) = 0.58
w2 = 0.37 + (0.1 * 0 * 0.6) = 0.37
b = -0.4 + (0.1 * 0) = -0.4
In this instance – you can probably observe that there are no updates since our expected output matches the perceptron output!
Iteration 3:
For the third example (0.5, 0.9) with target output 1:
Calculate total input (z)
= (w1 * x1) + (w2 * x2) + b
= (0.58 * 0.5) + (0.37 * 0.9) + (-0.4)
= 0.365
Predicted output = step_function(0.365) = 1 (since 0.365 >= 0)
Error = target output – predicted output = 1 - 1 = 0 (since the target class is 1 and predicted class is 1).
Update weights and bias: Since our predicted output matches our target output – there are no updates that need to be made in this iteration so we skip this step and go to the next iteration!
The fourth input (0.4, 0.1) produces a similar output to our previous 2 steps since the target output (0) matches our prediction using our current network weights, so we skip this step entirely. You get the point though. After more additional iterations, the perceptron continues to update its weights and bias based on the errors it encounters. The weights are continually adjusted to find the decision boundary that separates the two classes as accurately as possible. The training process would continue for more epochs until the model converges and the error becomes sufficiently small.
Visualizing Our Perceptron State
Let’s try to plot the evolution of our perceptron function throughout this example by plotting how our weights are moved in order to attempt to match our target output to our resultant output.
Our initial perceptron is basically divided a 3-d space according to the following rule / function:
def perceptron_function(x1, x2):
return 0.6 * x1 + 0.4 * x2 – 0.3We can plot this and visualize it in 3-d space using the Python script provided below:
import numpy as np
import matplotlib.pyplot as plt
# from mpl_toolkits.mplot3d import Axes3D
# Define the function modeled by the updated perceptron
def perceptron_function(x1, x2):
return 0.6 * x1 + 0.4 * x2 - 0.3
# Generate data points for plotting the function
x1_values = np.linspace(0, 1, 100) # Range of x1 values (0 to 1)
x2_values = np.linspace(0, 1, 100) # Range of x2 values (0 to 1)
x1_grid, x2_grid = np.meshgrid(x1_values, x2_values)
y_values = perceptron_function(x1_grid, x2_grid)
# Input data points
input_data = np.array([
[0.2, 0.3, 0],
[0.8, 0.6, 1],
[0.5, 0.9, 1],
[0.4, 0.1, 0]
])
# Create a 3D plot
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# Plot the function surface
ax.plot_surface(x1_grid, x2_grid, y_values, cmap='viridis', alpha=0.8)
# Plot the input points
for data_point in input_data:
x1, x2, target_output = data_point
color = 'red' if target_output == 1 else 'blue'
ax.scatter(x1, x2, perceptron_function(x1, x2), color=color, s=50)
# Add labels and title
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_zlabel('f(x1, x2)')
ax.set_title('Perceptron Function Model with Input Points')
# Show the plot
plt.show()The plot which we get (after doing a couple of small rotations) is provided:

As you can probably see – our function simply divides our input space by using a linear 2-d plane. Any points which are above the 0,0 division below this plane are automatically labeled as 0 while any points above this are labeled as 1. Looking more closely at our 2 bottom points, we can see that initially our first point (0.2, 0.3) is drawn above our binary division plane (0,0,0):

Because of this, our current perceptron classifies the input (0.2, 0.3) as being 1 instead of 0. To account for the error, our weights are adjusted and our plane slope is lowered while the bias is increased to produce the new function shown below:
def perceptron_function(x1, x2):
return 0.58 * x1 + 0.37 * x2 - 0.4After our training / update, we can visualize the new function and we should be able to see that our 2 points are now below the (0,0,0) plane and are thus pushed towards being classified as 0 (instead of 1) – which is now the correct label for our 2 inputs:

In other words – our perceptron essentially attempts to model a linear function. We adjust the linear function ‘weights’ to try to fit our inputs to produce the correct output.

We provide our target function output and initially assign a random function to ‘map’ our inputs to these outputs. Based on our target outputs – we then attempt to fit our weights to produce this target – and that in essence is all that a perceptron tries to do!!
Extending the perceptron network
Yes, a perceptron can have multiple inputs, but it is still a lonely neuron. The power of neural networks comes in the networking itself. Perceptrons are sadly incredibly limited in their abilities. If you read an AI textbook, it will say that a perceptron can only solve linearly separable problems. What’s a linearly separable problem?
Well – we just illustrated an example of one right above. It’s a problem within which we can divide our input space using a linear function. A simple one which can be visualized in 2-D space is provided below:

If you can classify the data with a straight line, then it is linearly separable (left). On the right, however, is non-linearly separable data. You can’t draw a straight line to separate the black dots from the gray ones. So how can we extend our perceptrons to be able to classify more complex data?
Easy!!
We extend our network and use multiple perceptrons!

The above diagram is known as a multi-layered perceptron -- a network of many neurons! Some are input neurons and receive the inputs, some are part of what’s called a “hidden” layer, and then there are the output neurons from which we read the results.
Training these networks is much more complicated that training a single perceptron! With one perceptron, we could easily evaluate how to change the weights according to the error. Here, there are so many different connections that we need to careful consider what direction to update our weights to fit our final output!
The solution to optimizing weights of a multi-layered network is known as backpropagation.
Backpropagation in a Nutshell
The backpropagation algorithm was a major milestone in machine learning. Before it was discovered, optimization methods were extremely unsatisfactory. One popular method was to perturb (adjust) the weights in a random direction (ie. increase or decrease) and see if the performance of the ANN increased. If it did not, one would attempt to either a) go in the other direction b) reduce the perturbation size or c) a combination of both. The above methodology though takes a very long time to discover the optimal weights and bias adjustments which we would need in order to provide accurate classifications!
Once again, the goal of any machine learning problem is to select weights and biases that provide the most optimal estimation of a function output which models the training data we feed in. For a simple perceptron – this may seem simple, but for a multi-layered one – things get a bit more complicated! Instead of having to update the weights and biases of one single neuron – we need to find a way to update the weights and biases of all of the neurons in our network layers!
Thankfully – there is a great tool which we can use to do this! It’s called calculus! How can we use calculus to adjust our weights?
Here is a sample diagram of a single-layered, shallow neural network:

As you can see, each neuron is a function of the previous one connected to it. In other words, if one were to change the value of w1, both “hidden 1” and “hidden 2” (and ultimately the output) neurons would change. Because of this notion of functional dependencies, we can mathematically formulate the output as an extensive composite function:
output = activation(w3 * hidden 2)
hidden 2 = activation(w2 * hidden 1)
hidden 1 = activation(w1 * input)
And thus we get:
output = activation(w3 * activation(w2 * activation(w1 * input)))
Here, the output is a composite function of the weights, inputs, and activation function(s). It is important to realize that the hidden units/nodes are simply intermediary computations that in actuality can be reduced down to computations of the input layer.
Let’s also attach a black box to the tail of our neural network which represents the error and call it ‘J’. This black box will compute and return the error (using a cost function) from our output:

If we were to take the derivative of the function with respect to some arbitrary weight (for example w1), we would iteratively apply the chain rule (once again using calculus) in order to attempt to minimize the error (J) of our above output.
The derivative of the error with any arbitrary weight can be modeled using the derivative function below:

Each of these derivatives can be simplified once we choose an activation and error function such that the entire result would represent a numerical value. At that point, any abstraction has been removed, and the error derivative can be used in an algorithm which is called gradient descent.
We don’t have the time to dive into the full details of backpropagation and gradient descent here, but I hope that you get the gist of what’s going on. If you’re looking for more info or a basic intuition on gradients and gradient descent, you can find my introduction to both concepts available in the link below:
A Brief Visual Introduction to Gradients and Gradient Descent
After doing so, you can get a great overview of how gradient descent and backpropagation work by viewing these great videos provided by 3Blue1Brown:
Gradient descent, how neural networks learn
What is backpropagation really doing?
You can also find a very simple implementation of a neural networks using the Numpy library in my AGI repository:
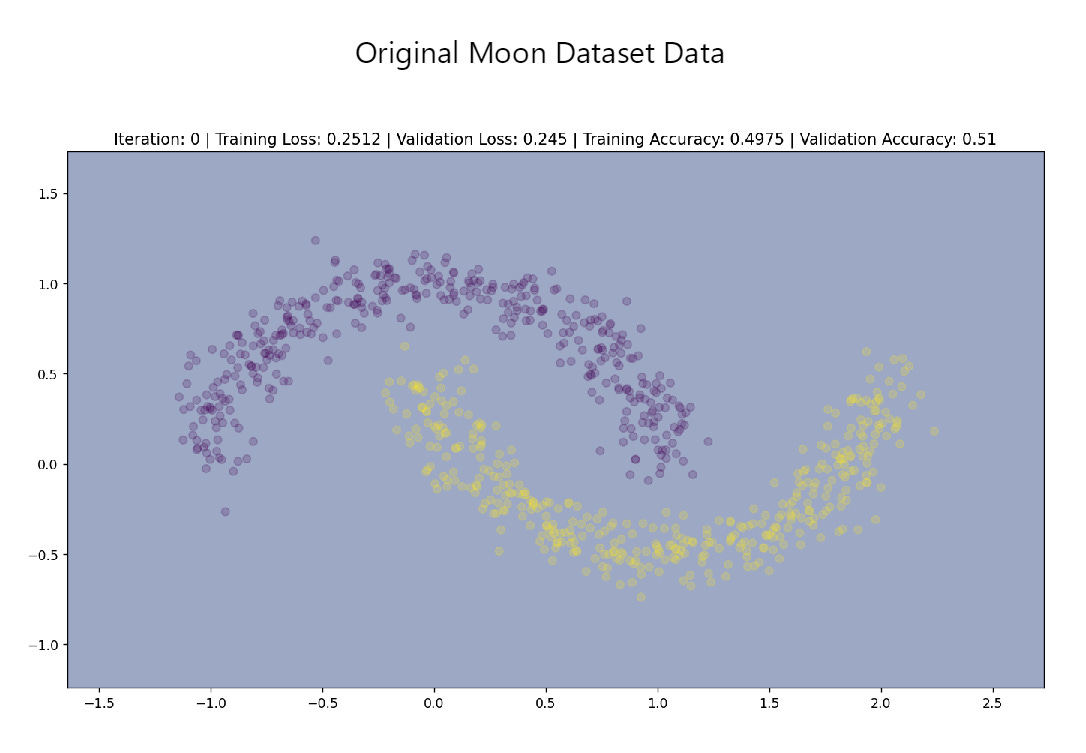
Another implementation which allows you to visualize the neural network architecture and decision boundary is available here. Using this implementation, we can see that the decision boundaries for multi-layered networks are definitely non-linear.
Blob Data Set Visuals


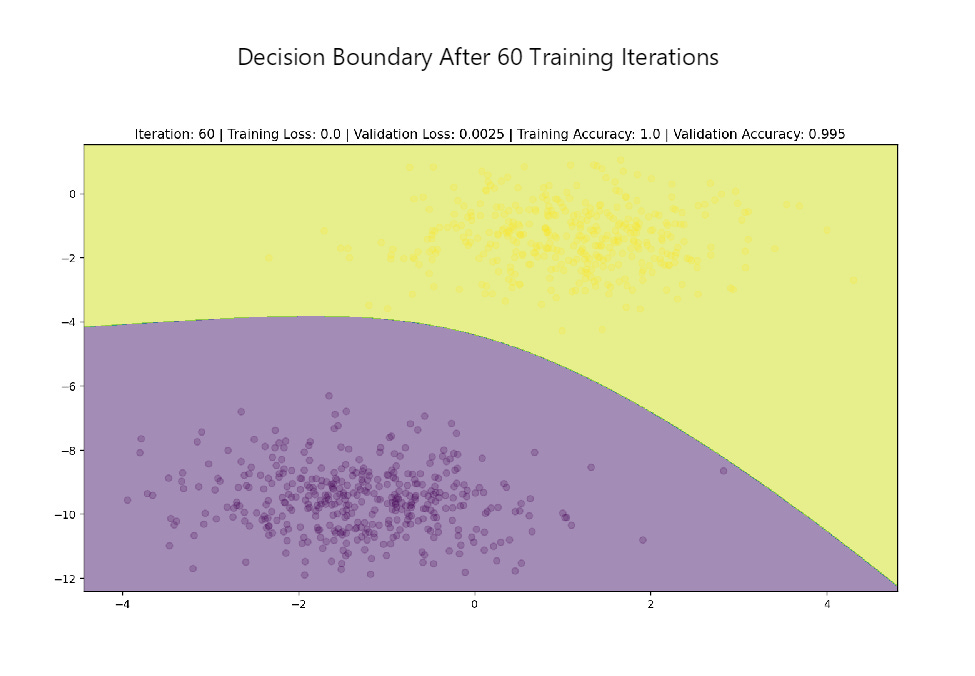
Moon Data Set Visuals


The Usefulness of Neural Networks
Neural networks had a slow start and faced significant challenges in their early days. Mostly due to limitations in computing power and a lack of data, their practical applications were severely restricted. It wasn't until recently that they truly began to showcase their potential and transform various aspects of modern life and business.
One of the key figures instrumental in propelling neural networks into the spotlight is Jeffrey Hinton, whose groundbreaking work in the 1980s and 1990s laid the foundation for modern deep learning. Hinton's played a vital role in developing the backpropagation algorithm which allowed neural networks to be trained much more efficiently than when they were originally conceived. Ever since then, there has been a resurgence of interest in them. Some notable areas where neural networks have transformed the modern world are provided below:
Natural Language Processing (NLP): Neural networks, especially large language models like ChatGPT have revolutionized NLP. These models can understand and generate human-like text and attempt to solve complex real-world problems in a fraction of the time that it takes humans to do so (albeit they also hallucinate and generate a lot of wrong answers as well).
Computer Vision: They power self-driving cars, medical image analysis, and quality control in manufacturing.
Financial Analysis: They’re used in predicting stock prices, fraud detection, credit scoring, and risk assessment, providing valuable insights for financial institutions.
Healthcare: In medical diagnosis, neural networks aid in identifying diseases from medical images, analyzing patient data, and discovering patterns in genetic data, leading to personalized treatment options.
Marketing and Customer Insights: Neural networks enable businesses to analyze vast amounts of customer data for personalized marketing, recommendation systems, and customer sentiment analysis.
In fact – the above answer was generated by ChatGPT itself! At the current moment, there are many other uses of neural nets. There are even discussions around their use in generative and generalized intelligence agents, but that discussion is a bit out of scope of our current introduction.
We’ll end our write up by simply stating that the usefulness and applicability of neural networks is unlimited and that human beings have only begun to unravel their incredible potential! Over the next few years, expect a lot more to come out from this incredible landscape as neural networks continue to evolve.
Hopefully you found this intro helpful! If you have any further question or suggestions, please feel free to leave a comment and I’ll make sure to address them as soon as I can!